最佳 AI 模型排行榜 —— 2026 年 6 月文本、编程、智能体、图像与视频全榜单(附数据来源)
指南更新于 16 分钟阅读
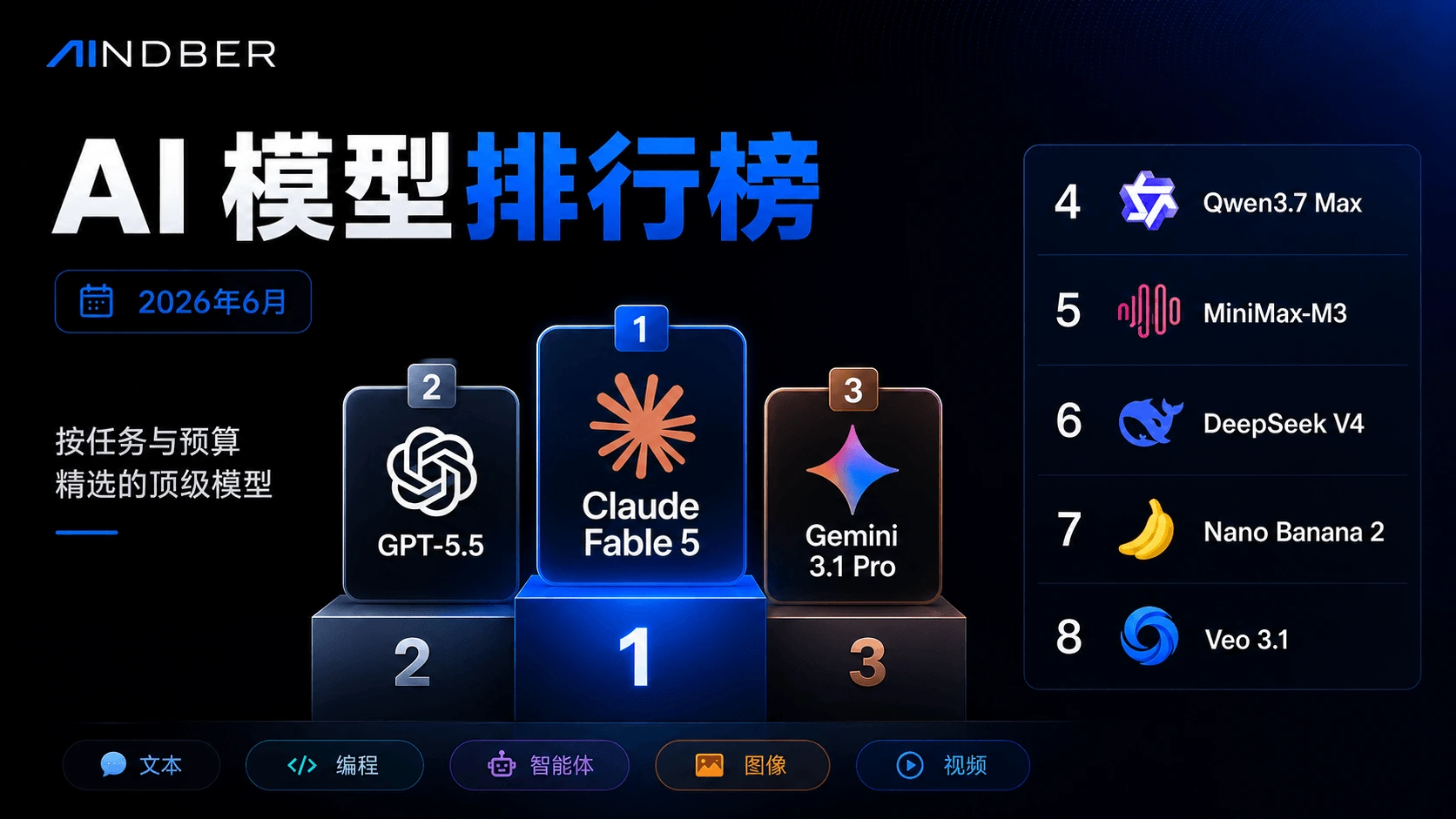
2026 年 6 月谁是最佳 AI 模型,取决于具体任务:Claude Fable 5 综合能力领先,GPT-5.5 称霸编程智能体,Gemini 3.1 Pro 性价比最佳。完整排名,附数据来源。
最后核实时间: 2026-06-15(新加坡时间/马来西亚时间)· 下次更新: 2026 年 7 月中旬。Mindber 数据快照 v2026.06。每一项数据均标注其公开来源与日期 —— 详见下文「方法与来源」。价格为混合/示意值,且变动频繁;在投入预算前请以各厂商的实时报价为准。
作者 Mindber Research · AI 模型追踪。数据已于 2026-06-15 对照所引用的排行榜核实。
我们如何评估: 这是一篇 AI 辅助的编辑分析,截至 2026 年 6 月,汇总了来自独立排行榜(Artificial Analysis、vals.ai、Scale AI SEAL、tbench.ai、τ²-bench、LMArena)以及厂商定价页面的公开结果。Mindber 并未自行运行私有基准测试,本文也不是实机产品测评。每一个数字都标注了其出处与日期;任何无法对照实时来源核实的数据,我们都会直接舍弃,而非凭空猜测。
简短结论: 2026 年 6 月并不存在单一的「最佳 AI 模型」—— 只有针对特定任务、特定预算的最佳模型。眼下,Claude Fable 5 在原始能力上居首,GPT-5.5 领跑编程智能体,Gemini 3.1 Pro 是性价比最高的前沿模型;开源权重模型(MiniMax-M3、DeepSeek V4、Qwen3.7 Max)以零头的价格弥补了大部分差距;Nano Banana 2 和 GPT Image 领跑图像生成;在 Sora 2 退役之后,Veo 3.1 / Kling 3.0 领跑视频生成。
下面是完整拆解 —— 更重要的是,多数排行榜都会跳过的那一部分:哪些数字是真的,哪些应该忽略。 想查看 Mindber 对同一领域的实时视图,请参阅 Model Arena 榜单与每周更新的 LLM 排名;想在价格与能力上对两个模型进行正面对比,请使用对比工具。
勾勒 2026 年 6 月格局的三个数字
65
Claude Fable 5 —— 登顶 Artificial Analysis Intelligence Index,领先性价比梯队约 8 分
Artificial Analysis,2026 年 6 月
83.4%
搭载 GPT-5.5 的 Codex CLI —— 在 Terminal-Bench 2.1 上领跑智能体编程,领先搭载 Opus 4.8 的 Claude Code(78.9%)
tbench.ai,2026 年 6 月
~$0.18
DeepSeek V4 Pro 每 100 万 token 的混合价格 —— 以约为顶级闭源模型十分之一的价格,提供接近前沿水平的质量
Artificial Analysis,2026 年 6 月
速览 —— 各类别最佳模型(2026 年 6 月)
| 任务 | 首选 | 最佳性价比替代 | 关键数字 |
|---|---|---|---|
| 文本与推理 | Claude Fable 5 | Gemini 3.1 Pro / Qwen3.7 Max | AA Intelligence Index 65 vs 57 |
| 编程(模型) | Claude Fable 5 / Opus 4.8 | DeepSeek V4 / MiniMax-M3 | SWE-bench Verified —— 但请阅读警示 |
| 编程智能体(工具) | GPT-5.5(Codex CLI) | Claude Opus 4.8(Claude Code) | Terminal-Bench 2.1:83.4% vs 78.9% |
| 通用智能体 / 工具调用 | GPT-5.5 | GLM-5 系列(客服类任务) | 因基准而异 —— 没有通用赢家 |
| 图像 | Nano Banana 2 | Seedream 5.0(大批量) | 人类偏好 Arena + 单图成本 |
| 视频 | Veo 3.1(电影质感 + 音频) | Kling 3.0(约 $0.10/秒) | Sora 2 即将关停 —— 尽快迁移 |
| 前沿质量中最便宜 | DeepSeek V4 Pro | MiniMax-M3 | 每 100 万 token 混合价约 $0.18–0.22 |
| 输出最快 | Mercury 2 | Gemini 3.1 Flash-Lite | 约 889 t/s vs 约 326 t/s |
能力数据:Artificial Analysis Intelligence Index,2026 年 6 月(381 个模型)。编程:vals.ai SWE-bench Verified + Scale AI SEAL。智能体:tbench.ai Terminal-Bench 2.1。我们为每一个数字标注其来源与日期 —— 详见下文方法。
本月有何变化
5 月末至 6 月初,前沿格局再度变动:
- Claude Fable 5 于 2026 年 6 月 9 日正式发布(GA)(每 100 万 token 收费 $10 / $50,上下文窗口 100 万 token)。它一登场便位列 Artificial Analysis Intelligence Index 榜首(65 分),并在 SWE-bench Verified 上拔得头筹(95.0%)。我们在 Claude Fable 5 指南中拆解了它的访问方式、安全防护与提示词,你也可以在 Anthropic 的官方公告中看到其自身定位。
- Claude Opus 4.8 于 2026 年 5 月 28 日发布($5 / $25)。它在 SWE-bench Verified 上取得 88.6%,在 Terminal-Bench 2.1 上取得 74.6% —— 是 Claude 产品线中性价比最强的一档。详见其评分卡,以及用于计算盈亏平衡点的 Opus 4.8 成本计算器。
- GPT-5.5(2026 年 4 月 23 日) 是 OpenAI 的默认日常模型,据称相比 GPT-5.4 幻觉率下降约 60%。目前它通过 Codex 领跑智能体编程;最新费率见 OpenAI 定价页面。
- Sora 2 即将退役。 OpenAI 已于 2026 年 4 月 26 日关停 Sora 网页版/应用,API 将于 2026 年 9 月 24 日关闭。请勿在其上启动新的视频流水线。
- 开源权重几乎追平。 DeepSeek V4、MiniMax-M3 和 Qwen3.7 Max 在 SWE-bench Verified 上现已与 Gemini 3.1 Pro 相差约 0.2 分 —— 而 token 价格仅为其十分之一左右。
核心要点:榜单顶端如今是一片高原,而非鸿沟。2026 年真正值得权衡的,是成本、速度与适配度 —— 而不是去追逐排名第一的那一行。
1)文本与推理
最干净的单一能力数字,是 Artificial Analysis Intelligence Index —— 它由 GPQA Diamond、MMLU-Pro、AIME、LiveCodeBench 等多项基准测试综合而成,归一化为单一分数。
| # | 模型 | 开发方 | Intelligence Index | 每 100 万 token 混合价 | 上下文 |
|---|---|---|---|---|---|
| 1 | Claude Fable 5(max effort) | Anthropic | 65 | $7.70 | 1M |
| 2 | Claude Opus 4.8(max) | Anthropic | 61 | $3.85 | 1M |
| 3 | GPT-5.5(xhigh) | OpenAI | 60 | $4.35 | 922k |
| 4 | GPT-5.5(high) | OpenAI | 59 | $4.35 | 922k |
| 5 | Gemini 3.1 Pro Preview | 57 | $1.74 | 1M | |
| 5 | Qwen3.7 Max | Alibaba | 57 | $1.43 | 1M |
| 5 | Claude Opus 4.7(max) | Anthropic | 57 | $3.85 | 1M |
| 8 | Gemini 3.5 Flash | 55 | $1.31 | 1M | |
| 8 | MiniMax-M3(开源) | MiniMax | 55 | $0.22 | 1M |
| 10 | Kimi K2.6(开源) | Moonshot | 54 | $0.70 | 256k |
来源:Artificial Analysis Intelligence Index,2026 年 6 月。
这样解读: 排名前五的模型在一套广泛的推理测试集上仅相差约 8 分 —— 差距小到对大多数真实工作负载而言,它们在质量上可以互换。真正拉开它们差距的是价格。Gemini 3.1 Pro 以 $1.74 提供 index-57 级别的推理能力;Qwen3.7 Max 以 $1.43 与之持平;MiniMax-M3 则以 $0.22 达到 index-55。只有面对真正最困难的那 5–10% 任务,支付 Fable-5 级别的价格(混合价 $7.70)才划算。如果你的开销主要来自大量中等难度的调用,那么性价比档位并非妥协 —— 它才是正确的默认选择,你也可以在 Mindber 排名上验证这一权衡。
人类偏好 vs 基准测试: LMArena(盲测 A/B 投票)与 Intelligence Index 衡量的是不同维度 —— 一个捕捉人们喜欢什么,另一个捕捉模型能做什么。Claude 与 Gemini 系列轮流占据 LMArena 文本榜的顶端,而这些排名每周都在变动。当两份排行榜结果不一致时,这一差距通常意味着某个模型在聊天风格上调校过度或不足,而不是某一份来源「错了」。这正是 Mindber 的评分方法论将能力与偏好作为两条独立坐标轴、而非合并为单一数字的原因。
2)编程
这是互联网上误导性数字最多的类别,请仔细阅读。
| # | 模型 | SWE-bench Verified | 每 100 万 token 价格(输入/输出) |
|---|---|---|---|
| 1 | Claude Fable 5 | 95.0% | $10 / $50 |
| 2 | Claude Opus 4.8 | 88.6% | $5 / $25 |
| 3 | GPT-5.5 | 82.6% | $5 / $30 |
| 4 | Claude Opus 4.7 | ~82% | $5 / $25 |
| 5 | MiniMax-M3(开源) | 80.5% | $0.30 / $1.20 |
| 5 | Gemini 3.5 Flash | 78.8% | $1.31 混合价 |
来源:vals.ai SWE-bench Verified,2026 年 6 月。(Opus 4.7 的公布得分在不同运行框架下从 82% 到 88% 不等 —— 详见警示。)
⚠️ 多数排行榜不会告诉你的现实核查
SWE-bench Verified 部分已被刷满,部分则被「背诵」了。 OpenAI 自己的审计发现,前沿模型能够逐字复现某些任务的「标准」补丁 —— 那 500 个 Python 问题在该基准被广泛公布之前,就已经泄漏进了训练数据。OpenAI 已停止公布 Verified 得分,转而推荐使用 SWE-bench Pro。
在 Scale AI 标准化的 SEAL 排行榜上(对每个模型采用完全相同的脚手架),这些数字全面崩塌:
- 最佳公开标准化得分:约 59.1%(GPT-5.4 xHigh)
- 私有商用题集:没有任何模型超过约 47.1%
- 从 Verified 转到 Pro 的典型下降幅度:15–35 分
所以当你看到「SWE-bench 95%」时,请把它翻译成:「这是一个被刷满的基准,在未见过的、更难的真实代码上,实际成功率大约只有这个数字的一半。」 采购决策请使用 Pro / 标准化数字,Verified 仅用于粗略的相对排名。更深一层的教训正是 Mindber 的验证方法论所极力强调的:一个头条基准数字只是一个起始假设,而不是一份采购决定。
3)智能体与工具调用
对于智能体类工作,运行框架与模型同样重要。 同一个模型在 Codex CLI、搭载 Opus 4.8 的 Claude Code 与自定义脚手架中得分各不相同 —— 智能体排行榜排的是智能体 + 模型的组合,而非单独的模型。
Terminal-Bench 2.1(通过终端操作一台真实计算机 —— 编译代码、搭建服务器、运行数据工作流):
| # | 智能体 + 模型 | 得分 |
|---|---|---|
| 1 | 搭载 GPT-5.5 的 Codex CLI | 83.4% |
| 2 | 搭载 Opus 4.8 的 Claude Code | 78.9% |
| 3 | 搭载 Gemini 3.1 Pro 的 Gemini CLI | 70.7%(±2.9) |
来源:tbench.ai,2026 年 6 月。
客服 / 结构化工具调用(τ²-bench): 情况完全不同 —— GLM 系列模型(例如 GLM-4.7-Flash,98.8%)在零售/航空类工具调用任务中居首。一个赢下终端自动化的模型,可能在多轮客服工具调用上落败。请按你实际运行的任务来挑选智能体,而不是凭单一榜单 —— 如果你拿不准哪些模型该进你的候选名单,可以先从按用例筛选的 AI 工具目录入手。
4)图像生成
图像赛道已经分化出清晰的细分车道 —— 不存在整体第一,只有各车道的最佳。
- 最佳全能 / 角色一致性: Nano Banana 2(Gemini 3.1 Flash Image)。原生 4K,在多次编辑中保持面部与风格稳定 —— 非常适合系列化内容(吉祥物、分镜、营销活动)。属于高端价位,约 $0.13–0.24/张。
- 最佳文本与排版: GPT Image(1.5 / 2)。一个会「思考」的潜空间,能够推理空间指令 —— 是唯一一个你可以放心让它把标题拼写正确的模型。在 Arena.ai 的提示词遵从度上始终名列前茅。
- 最佳性价比 / 大批量: Seedream 5.0(字节跳动)。生产级 4K,约 $0.026–0.032/张 —— 专为电商商品目录与内容日历打造。
- 最适合 Logo 与海报: Ideogram v3。
- 最适合品牌/风格锁定与开源权重: Flux 2 Pro(dev/pro/max 各档)。
- 最适合非英语提示词: Qwen Image(在中文、阿拉伯语、西班牙语上表现强劲)。
- 最快: Z-Image Turbo(每张约 1 秒)。
面向东南亚 / 多语言创作者: Qwen Image 和 Seedream 在处理中文及混合文字提示词时,比西方调校的模型更可靠,而 Seedream 的单图成本使得在小预算下批量出商品图成为现实。你可以在发现目录中浏览图像生成领域,并查看 Mindber 评分与实时报价。
5)视频生成
最大的看点是一次告别:Sora 2 即将关停(网页版/应用 2026 年 4 月 26 日;API 2026 年 9 月 24 日)。如果你正在使用它,请立即规划迁移。以下是剩下的竞争格局:
- 最佳电影质感 + 原生音频: Veo 3.1(Google)。唯一能生成 48kHz 同步对白(而不只是音效)的模型。在人物主体与自然光线上拥有最佳的照片级真实感。按档位约 $0.15–1.20/5 秒片段。
- 最佳性价比: Kling 3.0(快手)。原生 4K、60fps、多语言对口型,约 $0.10/秒 —— 迭代工作的主力。
- 最热门的图生视频: Seedance 2.0(字节跳动)。风格化运动表现强劲,擅长短视频竖屏内容。
- 新晋前沿挑战者: HappyHorse-1.0(阿里巴巴)。音视频联合生成,7 种语言对口型,正在 Artificial Analysis 视频榜上攀升;已在 fal.ai 上线。
- 最佳创作掌控力: Runway Gen-4.5。 运动笔刷、场景一致性以及真正的时间线编辑器 —— 它虽已失去排行榜领先地位,但在有导演意图的多镜头创作上仍然取胜。
- 最佳 HDR: Luma Ray3.14(原生 16-bit HDR)。
注意:视频竞技场得分采用不同的量纲(LMArena 文生视频 vs Artificial Analysis),因此跨榜单的数字比较并不可靠。请把它们视为各车道的领跑者,而非单一的排名阶梯。
6)最佳性价比与开源权重(自力更生车道)
如果你正在交付产品并紧盯利润率,这是本报告中最重要的一张表。开源权重如今已逼近前沿水平,而成本只是零头:
| 模型 | Index | 每 100 万 token 价格 | 为何选它 |
|---|---|---|---|
| Gemini 3.1 Pro | 57 | $1.74 | 最佳闭源前沿性价比 |
| Qwen3.7 Max | 57 | $1.43 | 前沿推理能力,1M 上下文,多语言表现强劲 |
| MiniMax-M3 (开源) | 55 | $0.22 | 接近前沿,开源权重,1M 上下文 |
| Kimi K2.6 (开源) | 54 | $0.70 | 开源推理能力强劲 |
| DeepSeek V4 Pro (开源) | 52 | $0.18 | 最便宜的可信主力;缓存命中可进一步压低输入成本 |
| GLM-5.1 (开源) | 51 | $0.90 | 工具调用 / 智能体能力强劲 |
来源:Artificial Analysis,2026 年 6 月。
路由策略: 成本最优的方案不是某一个模型 —— 而是一个路由器。把约 80% 的流量固定到一个便宜的主力模型(DeepSeek V4 / MiniMax-M3 / 某个小号 Gemini Flash),并把一个前沿模型(Opus 4.8 / Fable 5)保留给那困难的 20%。如果做得好,这在成本和质量上都能胜过任何单一模型的订阅方案。这一拆分的经济账 —— 以及为何标价单只占真实账单的一小部分 —— 在 《2026 年 AI 工具的真实成本》中有完整的端到端推演。
7)速度(用于实时场景与长智能体链)
当延迟在大量连续步骤中不断累积时,吞吐量就成了决定性指标:
- Mercury 2(Inception,扩散式 LLM)—— 约 889 tokens/秒
- Granite 4.0 H Small(IBM)—— 约 524 t/s
- Step 3.7 Flash —— 约 385 t/s
- gpt-oss-120b(high)—— 约 338 t/s
- Gemini 3.1 Flash-Lite —— 约 326 t/s
来源:Artificial Analysis 输出速度中位数,2026 年 6 月。 对于聊天体验,任何超过约 150 t/s 的速度都已让人感觉即时;速度最关键的场景是智能体循环和批处理任务,因为在链条中每多出一秒,都会被连续步骤的数量成倍放大。
如何真正挑选一个模型
别再为排名第一的那一行优化了。让模型匹配任务:
- 最难的推理、不计成本 → Claude Fable 5 或 Opus 4.8。
- 前沿水平下每美元最佳质量 → Gemini 3.1 Pro 或 Qwen3.7 Max。
- 自托管 / 数据驻留 / 最低成本 → MiniMax-M3、DeepSeek V4 或 Qwen3.7 Max。
- 在智能体内编程 → 通过 Codex 的 GPT-5.5,或通过 Claude Code 的 Opus 4.8。
- 图像 —— 通用 → Nano Banana 2;图中文本 → GPT Image;大批量 → Seedream 5。
- 视频 —— 电影质感 + 音频 → Veo 3.1;性价比/迭代 → Kling 3.0。
- 实时 / 高吞吐 → Mercury 2 或某个 Flash 档位模型。
下面的决策网格,就是把同样的逻辑整理成一份你可以直接交给采购方的表格:
采购方决策网格
质量优先于成本
最难的推理
- Claude Fable 5(index 65)或 Opus 4.8(61)
- 只有面对最难的 5–10% 任务才值得
- 把简单工作路由到别处 —— 别把这里当默认选项
每美元质量
前沿水平下的最佳性价比
- Gemini 3.1 Pro($1.74)或 Qwen3.7 Max($1.43)
- Index 57 —— 与榜首相差约 8 分以内
- 大多数生产流量的正确默认选择
利润率或数据驻留
最低成本 / 自托管
- MiniMax-M3($0.22)、DeepSeek V4($0.18)
- 开源权重,1M 上下文,可自托管
- 缓存命中可进一步压低输入费率
运行框架与模型同样重要
在智能体内编程
- 通过 Codex 的 GPT-5.5 在 Terminal-Bench 2.1 上居首
- 通过 Claude Code 的 Opus 4.8 紧随其后
- 请对智能体+模型的组合排名,而非单独的模型
各车道最佳,没有整体第一
图像与视频
- 图像:Nano Banana 2 / GPT Image / Seedream 5
- 视频:Veo 3.1(音频)或 Kling 3.0(性价比)
- Sora 2 API 于 2026 年 9 月 24 日关闭 —— 请迁移
延迟在智能体循环中不断累积
实时 / 高吞吐
- Mercury 2(约 889 t/s)或某个 Flash 档位模型
- >150 t/s 在聊天中就已感觉即时
- 对于批处理 + 多步骤链条,速度具有决定性
常见问题
眼下(2026 年 6 月)最佳的 AI 模型是哪一个?
论原始能力,Claude Fable 5 在 Artificial Analysis Intelligence Index 上领先(65)。但「最佳」取决于任务:GPT-5.5 领跑智能体编程,Gemini 3.1 Pro 性价比最高,而 MiniMax-M3 之类的开源模型最适合对成本敏感的部署。Mindber 的实时视图见 Model Arena 榜单。
Claude 比 GPT-5.5 更好吗?
在综合的 Intelligence Index 上,Claude Fable 5(65)和 Opus 4.8(61)排在 GPT-5.5(60)之上。在智能体编程(Terminal-Bench 2.1)上,通过 Codex 的 GPT-5.5(83.4%)目前略微领先于通过 Claude Code 的 Opus 4.8(78.9%)。它们足够接近,因此通常由工作流契合度和价格来决定胜负 —— Opus 4.8 成本计算器能帮你算清成本这一面。
最佳的免费或开源 AI 模型是哪一个?
MiniMax-M3(Intelligence Index 55)是最强的接近前沿的开源权重模型,其次是 Kimi K2.6(54)和 DeepSeek V4 Pro(52)。它们都可自托管,且远比闭源前沿模型便宜。
最便宜的好用 AI 模型是哪一个?
DeepSeek V4 Pro(每 100 万 token 混合价约 $0.18,index 52)和 MiniMax-M3(约 $0.22,index 55)以约为顶级闭源模型十分之一的价格,提供接近前沿水平的质量。
编程最佳的 AI 模型是哪一个?
论模型:Claude Fable 5 / Opus 4.8 在 SWE-bench Verified 上领先。论编程智能体:GPT-5.5(Codex)在 Terminal-Bench 2.1 上居首。请注意 SWE-bench Verified 已部分被刷满 —— 真实世界的信号请查看 SWE-bench Pro。
为什么 SWE-bench 得分那么高 —— 它们是真的吗?
对于 90%+ 的 SWE-bench Verified 得分,请谨慎对待。该基准存在已知的训练数据污染;OpenAI 已停止公布它。在 Scale 标准化的 SEAL 排行榜上,最佳公开得分约为 59%,而在私有题集上没有任何模型超过约 47%。真实世界的编程成功率,大约只有 Verified 头条数字的一半。
2026 年最佳的 AI 图像生成器是哪一个?
通用使用与角色一致性选 Nano Banana 2,文本/排版选 GPT Image,大批量、对成本敏感的生产选 Seedream 5.0。
既然 Sora 已经退场,现在最佳的 AI 视频生成器是哪一个?
电影质感配原生同步音频选 Veo 3.1,最佳性价比选 Kling 3.0(约 $0.10/秒)。Sora 2 的 API 于 2026 年 9 月 24 日关闭。
这份排行榜多久更新一次?
每月更新。这是 2026 年 6 月版;下次刷新将于 2026 年 7 月中旬发布。在两版之间,Model Arena 榜单与最新动态信息流会在新模型发布时实时追踪。
方法与来源
我们不运行自己的私有基准测试,也不编造分数。这份排行榜汇总来自独立来源的公开结果,并为每一项数据标注其出处与日期 —— 这种透明性正是重点所在,也是我们的评分方法论对每一个产品页面所坚持的同一标准。
- 能力 / 价格 / 速度: Artificial Analysis Intelligence Index(381 个模型),2026 年 6 月。
- 编程: vals.ai(SWE-bench Verified)与 Scale AI SEAL(SWE-bench Pro,标准化脚手架),2026 年 6 月。
- 智能体: tbench.ai(Terminal-Bench 2.1)与 τ²-bench,2026 年 6 月。
- 人类偏好: LMArena(盲测 A/B 投票),2026 年 6 月。
- 厂商定价与规格: Anthropic、OpenAI 与 Google Gemini 定价页面,2026 年 6 月。
价格为混合/示意值,且变动频繁 —— 在投入预算前请以各厂商的实时报价为准。一些研究预览版模型(例如 Mythos 档位的预览版)出现在排行榜上,但并未普遍开放;我们只对公开可用的领域进行排名。想全面了解一个模型在计入重试、输出不对称与闲置席位之后的真实成本,请阅读 《2026 年 AI 工具的真实成本》。
发现了错误或我们遗漏的新发布?这是改进一份排行榜最快的方式 —— 请告诉我们。
在 Mindber 上探索更多:实时 Model Arena 排名 · 最新动态 · 每周更新的 LLM 排名 · 完整的 AI 工具目录 · 我们全部的指南。
Mindber 上的相关文章
Share this article
法律声明
本出版物属于基于公开信息的编辑评论,不构成财务、法律、投资或专业建议。文中提及的产品名称、商标和注册商标均归其各自所有者所有;其出现并不代表认可或从属关系。Mindber 的分析反映基于公开信号的编辑判断,并可能随时变更,恕不另行通知。评分不是买入、卖出或持有建议。除非另有书面披露,Mindber 与被评估供应商不存在商业关系。本出版物受马来西亚法律管辖。因本出版物引起或与之相关的任何争议,均应提交马来西亚法院专属管辖。
AI 生成 · 本报告使用基于公开可得数据训练的 AI 语言模型生成。它反映生成时的编辑分析,并非实地产品测试、人工分析师独立验证或商业背书的结果。所有评分、评估和声明均来自 Mindber 在生成时索引的信号,并可能随时变更,恕不另行通知。Mindber 及其运营方不保证其准确性、完整性或适用于任何商业决策目的。本报告仅供信息参考。