โมเดล AI ที่ดีที่สุด จัดอันดับ — กระดานผู้นำเดือนมิถุนายน 2026 สำหรับงานข้อความ การเขียนโค้ด เอเจนต์ ภาพ และวิดีโอ (พร้อมแหล่งอ้างอิง)
คู่มืออัปเดต อ่าน 16 นาที
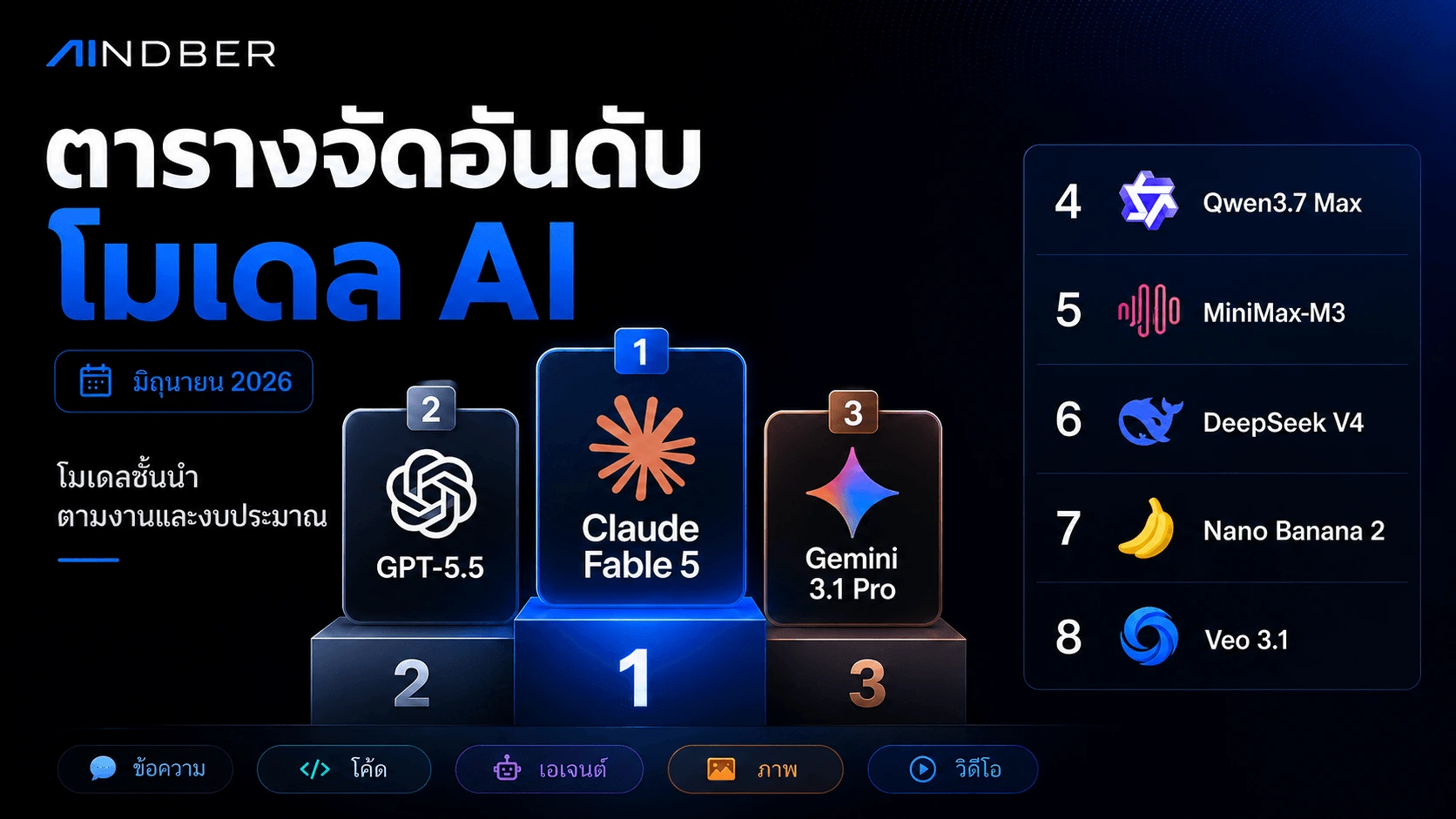
โมเดล AI ที่ดีที่สุดในเดือนมิถุนายน 2026 ขึ้นอยู่กับงาน: Claude Fable 5 นำด้านความสามารถ GPT-5.5 นำด้านเอเจนต์เขียนโค้ด Gemini 3.1 Pro คุ้มค่าที่สุด จัดอันดับพร้อมแหล่งอ้างอิง
ตรวจสอบล่าสุด: 2026-06-15 (SGT/MYT) · อัปเดตครั้งถัดไป: กลางเดือนกรกฎาคม 2026 Mindber Data Drop v2026.06 ทุกตัวเลขระบุที่มาและวันที่จากแหล่งที่เผยแพร่ไว้ — ดูหัวข้อ วิธีการและแหล่งอ้างอิง ด้านล่าง ราคาต่าง ๆ เป็นราคาเฉลี่ย/เพื่อการอ้างอิงและเปลี่ยนแปลงบ่อย โปรดตรวจสอบกับราคาจริงของผู้ให้บริการแต่ละรายก่อนตัดสินใจใช้จ่าย
โดย Mindber Research · ติดตามโมเดล AI ตัวเลขตรวจสอบกับกระดานผู้นำที่อ้างอิงไว้เมื่อ 2026-06-15
เราประเมินสิ่งนี้อย่างไร: การวิเคราะห์เชิงบรรณาธิการที่ใช้ AI ช่วย โดยรวบรวมผลที่เผยแพร่จากกระดานผู้นำอิสระ (Artificial Analysis, vals.ai, Scale AI SEAL, tbench.ai, τ²-bench, LMArena) และหน้าราคาของผู้จำหน่าย ณ เดือนมิถุนายน 2026 Mindber ไม่ได้รันเบนช์มาร์กส่วนตัวของตนเอง และนี่ไม่ใช่การทดสอบผลิตภัณฑ์ด้วยมือจริง ทุกตัวเลขระบุที่มาและวันที่กำกับไว้ ตัวเลขใดที่เรายืนยันกับแหล่งสดไม่ได้ จะถูกตัดออก ไม่ใช่เดาเอา
คำตอบสั้น ๆ: ไม่มี "โมเดล AI ที่ดีที่สุด" เพียงตัวเดียวในเดือนมิถุนายน 2026 — มีแต่โมเดลที่ดีที่สุด ตามงาน ตามงบประมาณ ในตอนนี้ Claude Fable 5 ครองความสามารถดิบสูงสุด GPT-5.5 นำด้านเอเจนต์เขียนโค้ด Gemini 3.1 Pro คุ้มค่าที่สุดในระดับแนวหน้า โมเดลแบบ open-weight (MiniMax-M3, DeepSeek V4, Qwen3.7 Max) ปิดช่องว่างได้เกือบหมดในราคาเพียงเศษเสี้ยว Nano Banana 2 และ GPT Image นำด้านภาพ และ Veo 3.1 / Kling 3.0 นำด้านวิดีโอแล้วในตอนนี้ที่ Sora 2 ถูกปลดระวางไป
ด้านล่างคือรายละเอียดทั้งหมด — และที่สำคัญกว่านั้นคือส่วนที่กระดานผู้นำส่วนใหญ่มักข้ามไป: ตัวเลขไหนเป็นของจริง และตัวเลขไหนควรมองข้าม สำหรับมุมมองสดของ Mindber ในสนามเดียวกันนี้ ดูกระดาน Model Arena และ การจัดอันดับ LLM รายสัปดาห์ หากต้องการเปรียบเทียบสองโมเดลแบบตัวต่อตัวทั้งราคาและความสามารถ ใช้ เครื่องมือเปรียบเทียบ
สามตัวเลขที่กำหนดกรอบเดือนมิถุนายน 2026
65
Claude Fable 5 — สูงสุดบน Artificial Analysis Intelligence Index นำกลุ่มระดับคุ้มค่าอยู่ราว 8 แต้ม
Artificial Analysis, มิถุนายน 2026
83.4%
Codex CLI บน GPT-5.5 — ผู้นำด้านเอเจนต์เขียนโค้ดบน Terminal-Bench 2.1 นำหน้า Claude Code บน Opus 4.8 (78.9%)
tbench.ai, มิถุนายน 2026
~$0.18
DeepSeek V4 Pro ราคาเฉลี่ยต่อ 1M tokens — คุณภาพใกล้เคียงระดับแนวหน้าในราคาราวหนึ่งในสิบของโมเดลปิดชั้นนำ
Artificial Analysis, มิถุนายน 2026
TL;DR — โมเดลที่ดีที่สุดแยกตามหมวด (มิถุนายน 2026)
| งาน | ตัวเลือกอันดับหนึ่ง | ทางเลือกคุ้มค่าที่สุด | ตัวเลขที่สำคัญ |
|---|---|---|---|
| ข้อความและการให้เหตุผล | Claude Fable 5 | Gemini 3.1 Pro / Qwen3.7 Max | AA Intelligence Index 65 เทียบ 57 |
| การเขียนโค้ด (โมเดล) | Claude Fable 5 / Opus 4.8 | DeepSeek V4 / MiniMax-M3 | SWE-bench Verified — แต่อ่านข้อควรระวัง |
| เอเจนต์เขียนโค้ด (เครื่องมือ) | GPT-5.5 (Codex CLI) | Claude Opus 4.8 (Claude Code) | Terminal-Bench 2.1: 83.4% เทียบ 78.9% |
| เอเจนต์ทั่วไป / การใช้เครื่องมือ | GPT-5.5 | ตระกูล GLM-5 (งานบริการลูกค้า) | ขึ้นอยู่กับเบนช์มาร์ก — ไม่มีผู้ชนะแบบครอบจักรวาล |
| ภาพ | Nano Banana 2 | Seedream 5.0 (ปริมาณมาก) | Arena ความชอบของมนุษย์ + ต้นทุนต่อภาพ |
| วิดีโอ | Veo 3.1 (ภาพยนตร์ + เสียง) | Kling 3.0 (~$0.10/วินาที) | Sora 2 กำลังถูกปิด — ย้ายออกไป |
| ถูกที่สุดในคุณภาพระดับแนวหน้า | DeepSeek V4 Pro | MiniMax-M3 | ~$0.18–0.22 เฉลี่ย /1M tokens |
| ส่งออกเร็วที่สุด | Mercury 2 | Gemini 3.1 Flash-Lite | ~889 t/s เทียบ ~326 t/s |
ตัวเลขความสามารถ: Artificial Analysis Intelligence Index, มิถุนายน 2026 (381 โมเดล) การเขียนโค้ด: vals.ai SWE-bench Verified + Scale AI SEAL เอเจนต์: tbench.ai Terminal-Bench 2.1 เราระบุที่มาและวันที่ของทุกตัวเลขกำกับไว้ — ดู วิธีการ ด้านล่าง
เดือนนี้มีอะไรเปลี่ยนแปลง
แนวหน้าขยับอีกครั้งในช่วงปลายเดือนพฤษภาคมถึงต้นเดือนมิถุนายน:
- Claude Fable 5 เปิดให้ใช้งานทั่วไป (GA) เมื่อวันที่ 9 มิถุนายน 2026 ($10 / $50 ต่อ 1M tokens, คอนเท็กซ์ 1M-token) เปิดตัวที่อันดับ #1 บน Artificial Analysis Intelligence Index (65) และสูงสุดบน SWE-bench Verified (95.0%) เราเจาะลึกการเข้าถึง มาตรการป้องกัน และพรอมป์ต่าง ๆ ใน คู่มือ Claude Fable 5 และคุณสามารถดูมุมมองของ Anthropic เองได้ใน ประกาศของบริษัท
- Claude Opus 4.8 ออกเมื่อวันที่ 28 พฤษภาคม 2026 ($5 / $25) ทำได้ 88.6% บน SWE-bench Verified และ 74.6% บน Terminal-Bench 2.1 — เป็นจุด ความสามารถต่อราคา ที่แข็งแกร่งที่สุดในสายผลิตภัณฑ์ Claude ดู สกอร์การ์ด และ เครื่องคำนวณต้นทุน Opus 4.8 สำหรับการคำนวณจุดคุ้มทุน
- GPT-5.5 (23 เมษายน 2026) เป็นโมเดลใช้งานทั่วไปที่ตั้งเป็นค่าเริ่มต้นของ OpenAI โดยมีรายงานว่าอาการหลอน (hallucinations) ลดลงราว ~60% เมื่อเทียบกับ GPT-5.4 ปัจจุบันนำด้านเอเจนต์เขียนโค้ดผ่าน Codex อัตราค่าใช้จ่ายปัจจุบันดูได้ที่ หน้าราคาของ OpenAI
- Sora 2 กำลังถูกปลดระวาง OpenAI ปิดเว็บ/แอป Sora เมื่อวันที่ 26 เมษายน 2026 และ API จะปิดในวันที่ 24 กันยายน 2026 อย่าเริ่มไปป์ไลน์วิดีโอใหม่บนระบบนี้
- โมเดล open weights ตามทันแทบหมดแล้ว ตอนนี้ DeepSeek V4, MiniMax-M3 และ Qwen3.7 Max อยู่ในระยะ ~0.2 แต้มจาก Gemini 3.1 Pro บน SWE-bench Verified — ในราคาราวหนึ่งในสิบของราคาต่อ token
ประเด็นพาดหัวสำคัญ: ส่วนยอดของตารางตอนนี้คือ ที่ราบสูง ไม่ใช่ช่องว่าง การตัดสินใจที่น่าสนใจในปี 2026 เป็นเรื่องของต้นทุน ความเร็ว และความเหมาะสม — ไม่ใช่การไล่ล่าแถวอันดับ #1
1) ข้อความและการให้เหตุผล
ตัวเลขความสามารถเดี่ยวที่ชัดเจนที่สุดคือ Artificial Analysis Intelligence Index — ค่ารวมจาก GPQA Diamond, MMLU-Pro, AIME, LiveCodeBench และเบนช์มาร์กอื่นอีกหลายตัว ปรับให้เป็นคะแนนเดียว
| # | โมเดล | ผู้สร้าง | Intelligence Index | ราคาเฉลี่ย /1M | คอนเท็กซ์ |
|---|---|---|---|---|---|
| 1 | Claude Fable 5 (max effort) | Anthropic | 65 | $7.70 | 1M |
| 2 | Claude Opus 4.8 (max) | Anthropic | 61 | $3.85 | 1M |
| 3 | GPT-5.5 (xhigh) | OpenAI | 60 | $4.35 | 922k |
| 4 | GPT-5.5 (high) | OpenAI | 59 | $4.35 | 922k |
| 5 | Gemini 3.1 Pro Preview | 57 | $1.74 | 1M | |
| 5 | Qwen3.7 Max | Alibaba | 57 | $1.43 | 1M |
| 5 | Claude Opus 4.7 (max) | Anthropic | 57 | $3.85 | 1M |
| 8 | Gemini 3.5 Flash | 55 | $1.31 | 1M | |
| 8 | MiniMax-M3 (open) | MiniMax | 55 | $0.22 | 1M |
| 10 | Kimi K2.6 (open) | Moonshot | 54 | $0.70 | 256k |
แหล่งที่มา: Artificial Analysis Intelligence Index, มิถุนายน 2026
อ่านแบบนี้: ห้าอันดับแรกห่างกันราว ~8 แต้มในชุดทดสอบการให้เหตุผลที่กว้าง — ใกล้พอที่สำหรับงานจริงส่วนใหญ่จะถือว่าใช้แทนกันได้ในด้านคุณภาพ จุดที่แยกกันชัดเจนคือ ราคา Gemini 3.1 Pro ให้การให้เหตุผลระดับ index-57 ในราคา $1.74 Qwen3.7 Max เทียบเท่าที่ $1.43 ส่วน MiniMax-M3 อยู่ที่ index-55 ที่ $0.22 การจ่ายในราคาระดับ Fable 5 ($7.70 เฉลี่ย) จะคุ้มก็ต่อเมื่อเป็นงานที่ยากที่สุดจริง ๆ ราว 5–10% เท่านั้น หากค่าใช้จ่ายของคุณส่วนใหญ่มาจากการเรียกใช้งานความยากปานกลางจำนวนมาก ระดับคุ้มค่าไม่ใช่การประนีประนอม — แต่คือค่าเริ่มต้นที่ถูกต้อง และคุณตรวจสอบความสมเหตุสมผลของการแลกเปลี่ยนนี้ได้บน การจัดอันดับ Mindber
ความชอบของมนุษย์เทียบกับเบนช์มาร์ก: LMArena (การโหวต A/B แบบปิดตา) และ Intelligence Index วัดสิ่งที่ต่างกัน — อันหนึ่งจับสิ่งที่ผู้คน ชอบ อีกอันจับสิ่งที่โมเดล ทำได้ ตระกูล Claude และ Gemini สลับกันครองยอดบนกระดานข้อความของ LMArena และอันดับเหล่านั้นเปลี่ยนทุกสัปดาห์ เมื่อกระดานผู้นำสองอันไม่ตรงกัน ช่องว่างนั้นมักหมายความว่าโมเดลถูกปรับจูนมากเกินหรือน้อยเกินสำหรับสไตล์การแชต ไม่ได้แปลว่าแหล่งหนึ่ง "ผิด" นี่คือเหตุผลว่าทำไม วิธีการให้คะแนน ของ Mindber จึงแยกความสามารถและความชอบเป็นสองแกนแทนที่จะยุบรวมเป็นตัวเลขเดียว
2) การเขียนโค้ด
นี่คือหมวดที่มีตัวเลขชวนเข้าใจผิดมากที่สุดบนอินเทอร์เน็ต ดังนั้นอ่านอย่างระมัดระวัง
| # | โมเดล | SWE-bench Verified | ราคา /1M (เข้า/ออก) |
|---|---|---|---|
| 1 | Claude Fable 5 | 95.0% | $10 / $50 |
| 2 | Claude Opus 4.8 | 88.6% | $5 / $25 |
| 3 | GPT-5.5 | 82.6% | $5 / $30 |
| 4 | Claude Opus 4.7 | ~82% | $5 / $25 |
| 5 | MiniMax-M3 (open) | 80.5% | $0.30 / $1.20 |
| 5 | Gemini 3.5 Flash | 78.8% | $1.31 เฉลี่ย |
แหล่งที่มา: vals.ai SWE-bench Verified, มิถุนายน 2026 (คะแนน Opus 4.7 ที่รายงานแตกต่างกันระหว่าง 82–88% ตาม harness ต่าง ๆ — ดูข้อควรระวัง)
⚠️ การตรวจสอบความเป็นจริงที่กระดานผู้นำส่วนใหญ่ไม่ยอมบอกคุณ
SWE-bench Verified อิ่มตัวบางส่วนและถูกท่องจำบางส่วน การตรวจสอบของ OpenAI เองพบว่าโมเดลระดับแนวหน้าสามารถสร้างแพตช์ "ทองคำ" คำต่อคำสำหรับบางงานได้ — โจทย์ Python จำนวน 500 ข้อรั่วไหลเข้าสู่ข้อมูลฝึกก่อนที่เบนช์มาร์กจะถูกเผยแพร่อย่างกว้างขวาง OpenAI หยุดรายงานคะแนน Verified และหันไปชี้ที่ SWE-bench Pro แทน
บนกระดานผู้นำมาตรฐาน SEAL ของ Scale AI (ใช้ scaffolding เดียวกันสำหรับทุกโมเดล) ตัวเลขร่วงลง:
- คะแนนมาตรฐานสาธารณะที่ดีที่สุด: ~59.1% (GPT-5.4 xHigh)
- ชุดเชิงพาณิชย์ส่วนตัว: ไม่มีโมเดลใดเกิน ~47.1%
- การลดลงโดยทั่วไปเมื่อย้ายจาก Verified → Pro: 15–35 แต้ม
ดังนั้นเมื่อคุณเห็น "95% บน SWE-bench" ให้แปลว่า: "เบนช์มาร์กที่อิ่มตัว อัตราความสำเร็จในโลกจริงราวครึ่งหนึ่งของนั้นบนโค้ดที่ยากกว่าและไม่เคยเห็นมาก่อน" ใช้ตัวเลข Pro / มาตรฐานสำหรับการตัดสินใจจัดซื้อ และใช้ Verified สำหรับการจัดอันดับเชิงเปรียบเทียบคร่าว ๆ เท่านั้น บทเรียนที่ลึกกว่านั้นคือสิ่งที่ วิธีการตรวจสอบ ของ Mindber ยึดถืออย่างหนักแน่น: ตัวเลขเบนช์มาร์กพาดหัวเป็นสมมติฐานตั้งต้น ไม่ใช่การตัดสินใจซื้อ
3) เอเจนต์และการใช้เครื่องมือ
สำหรับงานเอเจนต์ harness สำคัญพอ ๆ กับตัวโมเดล โมเดลเดียวกันทำคะแนนได้ต่างกันใน Codex CLI เทียบกับ Claude Code บน Opus 4.8 เทียบกับ scaffold ที่สร้างเอง — กระดานผู้นำเอเจนต์จัดอันดับ คู่เอเจนต์ + โมเดล ไม่ใช่โมเดลเดี่ยว ๆ
Terminal-Bench 2.1 (ใช้งานคอมพิวเตอร์จริงผ่านเทอร์มินัล — คอมไพล์โค้ด ตั้งค่าเซิร์ฟเวอร์ รันเวิร์กโฟลว์ข้อมูล):
| # | เอเจนต์ + โมเดล | คะแนน |
|---|---|---|
| 1 | Codex CLI บน GPT-5.5 | 83.4% |
| 2 | Claude Code บน Opus 4.8 | 78.9% |
| 3 | Gemini CLI บน Gemini 3.1 Pro | 70.7% (±2.9) |
แหล่งที่มา: tbench.ai, มิถุนายน 2026
บริการลูกค้า / การใช้เครื่องมือแบบมีโครงสร้าง (τ²-bench): ภาพต่างออกไปโดยสิ้นเชิง — โมเดลตระกูล GLM (เช่น GLM-4.7-Flash ที่ 98.8%) ครองงานเรียกใช้เครื่องมือด้านค้าปลีก/สายการบิน โมเดลที่ชนะการทำงานอัตโนมัติบนเทอร์มินัลอาจแพ้ในการใช้เครื่องมือบริการลูกค้าแบบหลายรอบ เลือกเอเจนต์ตามงานที่คุณรันจริง ไม่ใช่ตามกระดานเดียว — และถ้าคุณไม่แน่ใจว่าโมเดลไหนควรอยู่ในรายชื่อสั้น ๆ ของคุณ ให้เริ่มจาก ไดเรกทอรีเครื่องมือ AI ที่กรองตามกรณีการใช้งานของคุณ
4) การสร้างภาพ
การแข่งขันด้านภาพแยกออกเป็นช่องทางที่ชัดเจน — ไม่มีอันดับ #1 โดยรวม มีแต่ผู้นำที่ดีที่สุดในแต่ละช่องทาง
- ออลราวเดอร์ที่ดีที่สุด / ความสม่ำเสมอของตัวละคร: Nano Banana 2 (Gemini 3.1 Flash Image) 4K ดั้งเดิม คงใบหน้าและสไตล์ให้คงที่ข้ามการแก้ไข — เหมาะสำหรับคอนเทนต์ต่อเนื่อง (มาสคอต สตอรีบอร์ด แคมเปญ) ระดับพรีเมียมที่ ~$0.13–0.24/ภาพ
- ข้อความและตัวอักษรที่ดีที่สุด: GPT Image (1.5 / 2) พื้นที่แฝงแบบ "คิด" ที่ให้เหตุผลผ่านคำสั่งเชิงพื้นที่ — เป็นโมเดลเดียวที่คุณไว้ใจให้สะกดพาดหัวได้ถูกต้อง ได้คะแนนสูงสุดอย่างสม่ำเสมอบน Arena.ai ด้านการทำตามพรอมป์
- คุ้มค่าที่สุด / ปริมาณมาก: Seedream 5.0 (ByteDance) 4K ระดับการผลิตที่ ~$0.026–0.032/ภาพ — สร้างมาสำหรับแคตตาล็อกอีคอมเมิร์ซและปฏิทินคอนเทนต์
- ดีที่สุดสำหรับโลโก้และโปสเตอร์: Ideogram v3
- ดีที่สุดสำหรับการล็อกแบรนด์/สไตล์และ open weights: Flux 2 Pro (ระดับ dev/pro/max)
- ดีที่สุดสำหรับพรอมป์ที่ไม่ใช่ภาษาอังกฤษ: Qwen Image (แข็งแกร่งทั้งภาษาจีน อาหรับ สเปน)
- เร็วที่สุด: Z-Image Turbo (~1 วินาทีต่อภาพ)
สำหรับครีเอเตอร์เอเชียตะวันออกเฉียงใต้ / หลายภาษา: Qwen Image และ Seedream จัดการพรอมป์ภาษาจีนและพรอมป์ที่ผสมหลายระบบตัวอักษรได้น่าเชื่อถือกว่าโมเดลที่ปรับจูนแบบตะวันตก และเศรษฐศาสตร์ต่อภาพของ Seedream ทำให้การถ่ายภาพสินค้าเป็นชุดเป็นไปได้จริงบนงบประมาณน้อย คุณสามารถสำรวจสนามการสร้างภาพ พร้อมคะแนน Mindber และราคาสด ได้ใน ไดเรกทอรีสำรวจ
5) การสร้างวิดีโอ
เรื่องใหญ่คือ การจากลา: Sora 2 กำลังถูกปิด (เว็บ/แอป 26 เมษายน 2026; API 24 กันยายน 2026) ถ้าคุณใช้อยู่ วางแผนการย้ายตอนนี้เลย นี่คือสนามที่ยังเหลืออยู่:
- คุณภาพระดับภาพยนตร์ + เสียงดั้งเดิมที่ดีที่สุด: Veo 3.1 (Google) เป็นโมเดลเดียวที่สร้าง บทสนทนาที่ซิงค์ แบบ 48kHz — ไม่ใช่แค่เสียงประกอบ ภาพเสมือนจริงที่ดีที่สุดบนตัวแบบมนุษย์และแสงธรรมชาติ ~$0.15–1.20 ต่อคลิป 5 วินาที ตามระดับ
- คุ้มค่าที่สุด: Kling 3.0 (Kuaishou) 4K ดั้งเดิม 60fps ลิปซิงค์หลายภาษา ~$0.10/วินาที — ม้างานสำหรับการทำซ้ำ
- image-to-video ที่มาแรงที่สุด: Seedance 2.0 (ByteDance) การเคลื่อนไหวแบบมีสไตล์ที่แข็งแกร่งและคอนเทนต์แนวตั้งสั้น ๆ
- ผู้ท้าชิงแนวหน้าหน้าใหม่: HappyHorse-1.0 (Alibaba) เสียง-วิดีโอร่วมกัน ลิปซิงค์ 7 ภาษา กำลังไต่กระดานวิดีโอของ Artificial Analysis ใช้งานได้แล้วบน fal.ai
- ควบคุมเชิงสร้างสรรค์ได้ดีที่สุด: Runway Gen-4.5 แปรงเคลื่อนไหว ความสม่ำเสมอของฉาก และตัวแก้ไขไทม์ไลน์จริง — เสียตำแหน่งผู้นำบนกระดานผู้นำไปแล้ว แต่ยังชนะสำหรับงานหลายช็อตที่กำกับได้
- HDR ที่ดีที่สุด: Luma Ray3.14 (HDR 16-bit ดั้งเดิม)
หมายเหตุ: คะแนน arena วิดีโออยู่บนสเกลที่ต่างกัน (LMArena text-to-video เทียบกับ Artificial Analysis) ดังนั้นการเปรียบเทียบตัวเลขข้ามกระดานจึงไม่น่าเชื่อถือ ให้มองว่าเป็นผู้นำในแต่ละช่องทาง ไม่ใช่บันไดจัดอันดับเดียว
6) คุ้มค่าที่สุดและ open-weight (ช่องทางบูตสแตรป)
ถ้าคุณกำลังส่งมอบผลิตภัณฑ์และคอยจับตามาร์จิน นี่คือตารางที่สำคัญที่สุดในรายงานฉบับนี้ ตอนนี้ open weights ใกล้เคียงระดับแนวหน้าในราคาเพียงเศษเสี้ยว:
| โมเดล | Index | ราคา /1M | ทำไมต้องเลือก |
|---|---|---|---|
| Gemini 3.1 Pro | 57 | $1.74 | คุ้มค่าระดับแนวหน้า แบบปิด ที่ดีที่สุด |
| Qwen3.7 Max | 57 | $1.43 | การให้เหตุผลระดับแนวหน้า คอนเท็กซ์ 1M รองรับหลายภาษาได้ดี |
| MiniMax-M3 (open) | 55 | $0.22 | ใกล้ระดับแนวหน้า open weights คอนเท็กซ์ 1M |
| Kimi K2.6 (open) | 54 | $0.70 | การให้เหตุผลแบบ open ที่แข็งแกร่ง |
| DeepSeek V4 Pro (open) | 52 | $0.18 | ม้างานที่น่าเชื่อถือที่ถูกที่สุด; cache hits ลดต้นทุนอินพุตลงไปอีก |
| GLM-5.1 (open) | 51 | $0.90 | การใช้เครื่องมือ / งานเอเจนต์ที่แข็งแกร่ง |
แหล่งที่มา: Artificial Analysis, มิถุนายน 2026
กลยุทธ์การจัดเส้นทาง (routing): การตั้งค่าที่ดีที่สุดด้านต้นทุนไม่ใช่โมเดลเดียว — แต่คือตัวจัดเส้นทาง (router) ปักทราฟฟิกราว ~80% ไว้กับม้างานราคาถูก (DeepSeek V4 / MiniMax-M3 / Gemini Flash ตัวเล็ก) และสงวนโมเดลระดับแนวหน้า (Opus 4.8 / Fable 5) ไว้สำหรับงานยาก 20% ทำให้ถูกต้องแล้ว วิธีนี้เอาชนะการสมัครสมาชิกโมเดลเดียวได้ทั้งด้านต้นทุนและคุณภาพ เศรษฐศาสตร์ของการแบ่งสัดส่วนนี้ — และเหตุผลที่ป้ายราคาเป็นเพียงเศษเสี้ยวของบิลจริง — ถูกอธิบายอย่างละเอียดตั้งแต่ต้นจนจบใน ต้นทุนที่แท้จริงของเครื่องมือ AI ปี 2026
7) ความเร็ว (สำหรับงานเรียลไทม์และเชนเอเจนต์ยาว ๆ)
เมื่อความหน่วงสะสมข้ามขั้นตอนตามลำดับจำนวนมาก ปริมาณงาน (throughput) จะกลายเป็นตัวชี้ขาด:
- Mercury 2 (Inception, diffusion LLM) — ~889 tokens/sec
- Granite 4.0 H Small (IBM) — ~524 t/s
- Step 3.7 Flash — ~385 t/s
- gpt-oss-120b (high) — ~338 t/s
- Gemini 3.1 Flash-Lite — ~326 t/s
แหล่งที่มา: ความเร็วส่งออกค่ามัธยฐานของ Artificial Analysis, มิถุนายน 2026 สำหรับ UX การแชต อะไรที่เกิน ~150 t/s ก็รู้สึกว่าทันทีแล้ว ความเร็วสำคัญที่สุดสำหรับลูปเอเจนต์และงานแบบ batch ซึ่งทุกวินาทีที่เพิ่มขึ้นจะถูกคูณด้วยจำนวนขั้นตอนตามลำดับในเชน
วิธีเลือกโมเดลจริง ๆ
หยุดปรับให้เข้ากับแถวอันดับ #1 จับคู่โมเดลให้เข้ากับงาน:
- การให้เหตุผลที่ยากที่สุด ไม่เกี่ยงเงิน → Claude Fable 5 หรือ Opus 4.8
- คุณภาพต่อดอลลาร์ที่ดีที่สุดในระดับแนวหน้า → Gemini 3.1 Pro หรือ Qwen3.7 Max
- โฮสต์เอง / ที่ตั้งของข้อมูล / ต้นทุนต่ำสุด → MiniMax-M3, DeepSeek V4 หรือ Qwen3.7 Max
- เขียนโค้ดภายในเอเจนต์ → GPT-5.5 ผ่าน Codex หรือ Opus 4.8 ผ่าน Claude Code
- ภาพ — ทั่วไป → Nano Banana 2; ข้อความในภาพ → GPT Image; ปริมาณมาก → Seedream 5
- วิดีโอ — ภาพยนตร์ + เสียง → Veo 3.1; คุ้มค่า/การทำซ้ำ → Kling 3.0
- เรียลไทม์ / ปริมาณงานสูง → Mercury 2 หรือโมเดลระดับ Flash
ตารางการตัดสินใจด้านล่างคือตรรกะเดียวกันในรูปแบบที่คุณส่งต่อให้ผู้ซื้อได้:
ตารางการตัดสินใจสำหรับผู้ซื้อ
คุณภาพเหนือต้นทุน
การให้เหตุผลที่ยากที่สุด
- Claude Fable 5 (index 65) หรือ Opus 4.8 (61)
- คุ้มค่าสำหรับงานที่ยากที่สุด 5–10%
- จัดเส้นทางงานง่าย ๆ ไปที่อื่น — อย่าตั้งเป็นค่าเริ่มต้นที่นี่
คุณภาพต่อดอลลาร์
คุ้มค่าที่สุดในระดับแนวหน้า
- Gemini 3.1 Pro ($1.74) หรือ Qwen3.7 Max ($1.43)
- Index 57 — อยู่ในระยะ ~8 แต้มจากยอดสุด
- ค่าเริ่มต้นที่ถูกต้องสำหรับทราฟฟิกการผลิตส่วนใหญ่
มาร์จินหรือที่ตั้งของข้อมูล
ต้นทุนต่ำสุด / โฮสต์เอง
- MiniMax-M3 ($0.22), DeepSeek V4 ($0.18)
- Open weights, คอนเท็กซ์ 1M, โฮสต์เองได้
- Cache hits ลดอัตราอินพุตลงไปอีก
harness สำคัญพอ ๆ กับโมเดล
เขียนโค้ดภายในเอเจนต์
- GPT-5.5 ผ่าน Codex ครองยอด Terminal-Bench 2.1
- Opus 4.8 ผ่าน Claude Code ตามมาติด ๆ
- จัดอันดับคู่เอเจนต์+โมเดล ไม่ใช่โมเดลเดี่ยว ๆ
ดีที่สุดในแต่ละช่องทาง ไม่มีอันดับ #1 โดยรวม
ภาพและวิดีโอ
- ภาพ: Nano Banana 2 / GPT Image / Seedream 5
- วิดีโอ: Veo 3.1 (เสียง) หรือ Kling 3.0 (คุ้มค่า)
- API ของ Sora 2 ปิด 24 ก.ย. 2026 — ย้าย
ความหน่วงสะสมในลูปเอเจนต์
เรียลไทม์ / ปริมาณงานสูง
- Mercury 2 (~889 t/s) หรือโมเดลระดับ Flash
- >150 t/s ก็รู้สึกว่าทันทีในการแชตแล้ว
- ความเร็วชี้ขาดสำหรับงาน batch + เชนหลายขั้นตอน
คำถามที่พบบ่อย
โมเดล AI ที่ดีที่สุดตอนนี้คืออะไร (มิถุนายน 2026)?
สำหรับความสามารถดิบ Claude Fable 5 นำ Artificial Analysis Intelligence Index (65) แต่ "ดีที่สุด" ขึ้นอยู่กับงาน: GPT-5.5 นำด้านเอเจนต์เขียนโค้ด Gemini 3.1 Pro คุ้มค่าที่สุด และโมเดล open อย่าง MiniMax-M3 ดีที่สุดสำหรับการนำไปใช้งานที่อ่อนไหวต่อต้นทุน มุมมองสดของ Mindber อยู่บนกระดาน Model Arena
Claude ดีกว่า GPT-5.5 ไหม?
บน Intelligence Index แบบรวม Claude Fable 5 (65) และ Opus 4.8 (61) อยู่เหนือ GPT-5.5 (60) ด้านเอเจนต์เขียนโค้ด (Terminal-Bench 2.1) GPT-5.5 ผ่าน Codex (83.4%) ปัจจุบันเฉือนเอาชนะ Opus 4.8 ผ่าน Claude Code (78.9%) พวกมันใกล้กันพอที่ความเข้ากันได้กับเวิร์กโฟลว์และราคามักเป็นตัวตัดสิน — เครื่องคำนวณต้นทุน Opus 4.8 ช่วยในด้านเงิน
โมเดล AI ฟรีหรือโอเพนซอร์สที่ดีที่สุดคืออะไร?
MiniMax-M3 (Intelligence Index 55) เป็นโมเดล open-weight ใกล้ระดับแนวหน้าที่แข็งแกร่งที่สุด ตามด้วย Kimi K2.6 (54) และ DeepSeek V4 Pro (52) ทั้งหมดโฮสต์เองได้และถูกกว่าโมเดลปิดระดับแนวหน้าอย่างมาก
โมเดล AI ที่ดีและถูกที่สุดคืออะไร?
DeepSeek V4 Pro ($0.18 เฉลี่ย /1M tokens, index 52) และ MiniMax-M3 ($0.22, index 55) ให้คุณภาพใกล้เคียงระดับแนวหน้าในราคาราวหนึ่งในสิบของโมเดลปิดชั้นนำ
โมเดล AI ที่ดีที่สุดสำหรับการเขียนโค้ดคืออะไร?
แยกตามโมเดล: Claude Fable 5 / Opus 4.8 นำ SWE-bench Verified แยกตาม เอเจนต์ เขียนโค้ด: GPT-5.5 (Codex) ครองยอด Terminal-Bench 2.1 หมายเหตุ SWE-bench Verified อิ่มตัวบางส่วน — ตรวจสอบ SWE-bench Pro สำหรับสัญญาณในโลกจริง
ทำไมคะแนน SWE-bench ถึงสูงนัก — เป็นของจริงไหม?
ให้ระมัดระวังคะแนน SWE-bench Verified ที่ 90%+ เบนช์มาร์กนี้มีการปนเปื้อนข้อมูลฝึกที่รู้กันอยู่ OpenAI หยุดรายงานมันไปแล้ว บนกระดานผู้นำมาตรฐาน SEAL ของ Scale คะแนนสาธารณะที่ดีที่สุดคือ ~59% และไม่มีโมเดลใดเกิน ~47% บนชุดส่วนตัว ความสำเร็จในการเขียนโค้ดในโลกจริงราวครึ่งหนึ่งของพาดหัว Verified
โปรแกรมสร้างภาพ AI ที่ดีที่สุดในปี 2026 คืออะไร?
Nano Banana 2 สำหรับการใช้งานทั่วไปและความสม่ำเสมอของตัวละคร GPT Image สำหรับข้อความ/ตัวอักษร และ Seedream 5.0 สำหรับการผลิตปริมาณมากที่อ่อนไหวต่อต้นทุน
โปรแกรมสร้างวิดีโอ AI ที่ดีที่สุดตอนนี้ที่ Sora หายไปแล้วคืออะไร?
Veo 3.1 สำหรับคุณภาพระดับภาพยนตร์พร้อมเสียงซิงค์ดั้งเดิม และ Kling 3.0 สำหรับความคุ้มค่าที่สุด (~$0.10/วินาที) API ของ Sora 2 ปิดตัวลงในวันที่ 24 กันยายน 2026
กระดานผู้นำนี้อัปเดตบ่อยแค่ไหน?
ทุกเดือน นี่คือฉบับเดือนมิถุนายน 2026 การอัปเดตครั้งถัดไปจะมาในกลางเดือนกรกฎาคม 2026 ระหว่างฉบับต่าง ๆ กระดาน Model Arena และฟีด มีอะไรใหม่ จะติดตามการเปิดตัวเมื่อเกิดขึ้น
วิธีการและแหล่งอ้างอิง
เราไม่ได้รันเบนช์มาร์กส่วนตัวของเราเองหรือกุคะแนนขึ้นมา กระดานผู้นำนี้ รวบรวมผลที่เผยแพร่จากแหล่งอิสระและระบุที่มาและวันที่ของทุกตัวเลขกำกับไว้ — ความโปร่งใสนั้นคือหัวใจ และเป็นมาตรฐานเดียวกับที่ วิธีการให้คะแนน ของเรายึดถือกับทุกหน้าผลิตภัณฑ์
- ความสามารถ / ราคา / ความเร็ว: Artificial Analysis Intelligence Index (381 โมเดล), มิถุนายน 2026
- การเขียนโค้ด: vals.ai (SWE-bench Verified) และ Scale AI SEAL (SWE-bench Pro, scaffolding มาตรฐาน), มิถุนายน 2026
- เอเจนต์: tbench.ai (Terminal-Bench 2.1) และ τ²-bench, มิถุนายน 2026
- ความชอบของมนุษย์: LMArena (การโหวต A/B แบบปิดตา), มิถุนายน 2026
- ราคาและสเปกของผู้จำหน่าย: หน้าราคาของ Anthropic, OpenAI และ Google Gemini, มิถุนายน 2026
ราคาต่าง ๆ เป็นราคาเฉลี่ย/เพื่อการอ้างอิงและเปลี่ยนแปลงบ่อย — โปรดตรวจสอบกับราคาจริงของผู้ให้บริการแต่ละรายก่อนตัดสินใจใช้จ่าย โมเดล research-preview บางตัว (เช่น พรีวิวระดับ Mythos) ปรากฏบนกระดานผู้นำแต่ยังไม่เปิดให้ใช้งานทั่วไป เราจัดอันดับสนามที่ ใช้งานได้ต่อสาธารณะ เท่านั้น สำหรับภาพรวมทั้งหมดว่าโมเดลหนึ่งมีต้นทุนเท่าไรจริง ๆ เมื่อนับรวมการลองใหม่ ความไม่สมดุลของเอาต์พุต และที่นั่งที่ไม่ได้ใช้ อ่าน ต้นทุนที่แท้จริงของเครื่องมือ AI ปี 2026
พบข้อผิดพลาดหรือการเปิดตัวใหม่ที่เราพลาดไปไหม? นั่นคือวิธีที่เร็วที่สุดในการพัฒนากระดานผู้นำ — บอกเรามา
สำรวจเพิ่มเติมบน Mindber: การจัดอันดับ Model Arena แบบสด · มีอะไรใหม่ · การจัดอันดับ LLM รายสัปดาห์ · ไดเรกทอรีเครื่องมือ AI ทั้งหมด · คู่มือ ทั้งหมดของเรา
บทความที่เกี่ยวข้องบน Mindber
ต้นทุนที่แท้จริงของเครื่องมือ AI ในปี 2026: ราคาป้ายเทียบกับความเป็นจริง
ทำไมต้นทุนที่แท้จริงของเครื่องมือ AI จึงสูงราว ~8 เท่าของราคาป้าย — โมเดล TCO ที่อ้างอิงครบถ้วนพร้อมเจ็ดต้นทุนที่ซ่อนอยู่
เครื่องคำนวณต้นทุน Opus 4.8: เมื่อไรที่เอาชนะ Sonnet และ GPT-5.5
ปริมาณงานจุดคุ้มทุน การประหยัดด้วยการจัดเส้นทางอัจฉริยะ และอัตรา cache ต่อโมเดลสำหรับโมเดลระดับแนวหน้าปัจจุบัน
Claude Fable 5: มันคืออะไร ใช้อย่างไร และพรอมป์ที่ดึงศักยภาพออกมาได้เต็มที่
โมเดลระดับ Mythos สาธารณะตัวแรกของ Anthropic — ราคา มาตรการป้องกัน เบนช์มาร์ก การเข้าถึง และพรอมป์แบบคัดลอกวาง
Share this article
ประกาศทางกฎหมาย
สิ่งพิมพ์นี้เป็นบทวิจารณ์เชิงบรรณาธิการจากข้อมูลสาธารณะ และไม่ใช่คำแนะนำทางการเงิน กฎหมาย การลงทุน หรือวิชาชีพ ชื่อผลิตภัณฑ์ เครื่องหมายการค้า และเครื่องหมายการค้าจดทะเบียนที่กล่าวถึงเป็นทรัพย์สินของเจ้าของแต่ละราย การปรากฏของชื่อเหล่านั้นไม่ได้หมายถึงการรับรองหรือความเกี่ยวข้อง การวิเคราะห์ของ Mindber สะท้อนดุลยพินิจเชิงบรรณาธิการจากสัญญาณสาธารณะและอาจเปลี่ยนแปลงได้โดยไม่ต้องแจ้งให้ทราบ คะแนนไม่ใช่คำแนะนำให้ซื้อ ขาย หรือถือครอง ไม่มีความสัมพันธ์ทางการค้าระหว่าง Mindber กับผู้ให้บริการที่ประเมิน เว้นแต่จะเปิดเผยเป็นลายลักษณ์อักษร สิ่งพิมพ์นี้อยู่ภายใต้กฎหมายของมาเลเซีย ข้อพิพาทใด ๆ ที่เกิดจากหรือเกี่ยวข้องกับสิ่งพิมพ์นี้ให้อยู่ภายใต้เขตอำนาจศาลเฉพาะของศาลมาเลเซีย
สร้างโดย AI · รายงานนี้สร้างขึ้นโดยใช้โมเดลภาษา AI ที่ฝึกจากข้อมูลที่เปิดเผยต่อสาธารณะ รายงานสะท้อนการวิเคราะห์เชิงบรรณาธิการ ณ เวลาที่สร้าง และไม่ได้เป็นผลจากการทดสอบผลิตภัณฑ์โดยตรง การตรวจสอบอิสระโดยนักวิเคราะห์มนุษย์ หรือการรับรองเชิงพาณิชย์ คะแนน การประเมิน และข้อกล่าวอ้างทั้งหมดมาจากสัญญาณที่ Mindber จัดทำดัชนี ณ เวลาที่สร้าง และอาจเปลี่ยนแปลงได้โดยไม่ต้องแจ้งให้ทราบ Mindber และผู้ดำเนินการไม่รับประกันความถูกต้อง ความครบถ้วน หรือความเหมาะสมสำหรับวัตถุประสงค์ในการตัดสินใจเชิงพาณิชย์ใด ๆ รายงานนี้มีไว้เพื่อให้ข้อมูลเท่านั้น