Loop Engineering: por qué los mejores ingenieros dejaron de promptear su IA
GuíaActualizado 8 min de lectura
Diseña el sistema que promptea a tus agentes de IA, no los prompts. Qué funciona hoy en producción, qué no, y cuándo conviene saltárselo por completo.

Última verificación: 2026-06-17. Las afirmaciones atribuidas a Peter Steinberger, Boris Cherny y Addy Osmani provienen de sus publicaciones y ensayos públicos a esta fecha. El campo avanza rápido — consulta las fuentes enlazadas para conocer las posturas más actuales.
Por Frankie C. · Investigador de Mercado Senior, Mindber. Rastrea más de 500 herramientas de IA/SaaS en los mercados del SEA mediante la metodología Mindber Innovation Index.
El 7 de junio de 2026, un desarrollador llamado Peter Steinberger publicó dos frases que acumularon millones de visualizaciones y reabrieron una discusión que el mundo del coding con IA creía zanjada. Su punto: deja de teclear prompts en tu agente de programación. Construye el sistema que los promptee por ti. Días antes, Boris Cherny — que dirige Claude Code en Anthropic — había hecho la misma observación desde dentro: ya no promptea el modelo. Escribe loops, y los loops hacen el prompteo.
Para entender cómo Mindber puntúa las herramientas que importan aquí, consulta la categoría de agentes de programación con IA y la metodología detrás del Mindber Innovation Index.
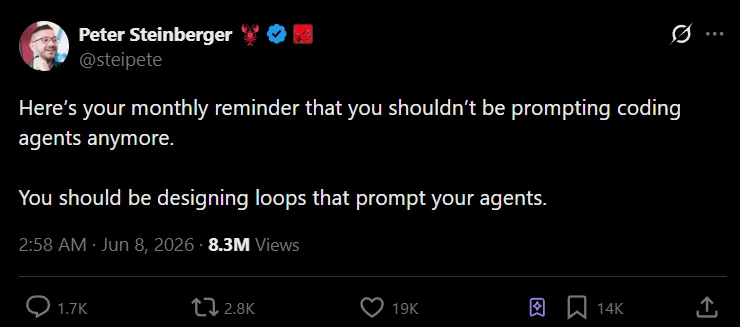
La publicación que reabrió el debate: Peter Steinberger sobre construir el loop en lugar de teclear los prompts. Fuente: Peter Steinberger en X, junio de 2026.
Esa idea ya tiene nombre: loop engineering. Casi toda la cobertura desde entonces ha sido grandilocuente. Esta es la versión sin hype — qué es, qué funciona hoy en producción, qué todavía no, y cuándo no construir un loop en absoluto.
¿Qué es el loop engineering?
El loop engineering es la práctica de diseñar un sistema que ejecuta un agente de IA en ciclos — fija un objetivo, toma una acción, observa el resultado, reflexiona y repite — hasta cumplir el objetivo o hasta que el sistema devuelva el control a una persona.
El cambio gira en torno a quién hace el prompteo. En lugar de que un desarrollador guíe al agente turno a turno, construye el loop que lo guía. Steinberger (creador del proyecto de agente de código abierto OpenClaw, ahora en OpenAI) describió el trabajo como diseñar "loops que prompteen a tus agentes". Addy Osmani, el ingeniero de Google cuyo ensayo sobre loop engineering se convirtió en el texto de referencia, describe un loop como un objetivo recursivo: define el propósito, itera hasta terminar.
La prueba de una línea: Si te descubres re-ejecutando el mismo prompt — con un contexto ligeramente distinto cada vez — ya tienes un loop manual. El loop engineering es lo que construyes para dejar de hacerlo a mano.
Dónde encaja el loop engineering: las cuatro capas del stack
El loop engineering no surgió de la nada. Es la cima de un stack que creció a medida que los agentes se volvían más capaces. Cada capa responde a una pregunta fundamentalmente distinta.
Las cuatro capas de la ingeniería de IA — cada una se apoya en la anterior
- 1
Prompt Engineering
La etapa tempranaLa pregunta que responde: ¿cómo formulo una sola petición? Lo que controlas: la redacción de una única entrada. La palanca central es la expresión humana precisa — pedirle al modelo con suficiente claridad para elevar su comprensión de un prompt. - 2
Context / Workflow Engineering
La etapa intermediaLa pregunta: ¿cómo encadeno pasos y aporto contexto de fondo? Lo que controlas: la información y la secuencia que ve el agente. Cadenas de lógica determinista más un contexto de proyecto más completo elevan la comprensión del modelo de una tarea grande y de varios pasos. - 3
Harness Engineering
La capa de ejecuciónLa pregunta: ¿cómo equipo una ejecución del agente? Lo que controlas: herramientas, permisos y señales verificables — ejecuta el código, lee el error. Construyes el entorno de ejecución y le das al agente las herramientas, los accesos y las señales de ejecución comprobables adecuadas. - 4
Loop Engineering
La frontera actualLa pregunta: ¿cómo mantengo al agente ejecutándose y mejorando por su cuenta? Lo que controlas: el sistema que dispara, asigna, verifica, persiste el estado y decide qué sigue — un loop cerrado que permite al agente autocorregirse en lugar de esperar a que una persona lo revise.
La forma limpia de sostener la distinción: el harness equipa una sola ejecución; el loop es lo que sigue picando al agente según un calendario, genera ayudantes, se realimenta a lo largo de muchas ejecuciones y capitaliza lo que aprende.
Casi todo el debate sobre "promptear vs. ingeniería" colapsa todo este stack en una sola cosa. No son lo mismo, y confundirlos produce la herramienta equivocada para el trabajo en cada capa.
Anatomía de un loop de verdad
El modelo mental que la mayoría tiene de un agente: Objetivo → Plan → Ejecutar → Salida. Ahí se detienen — y por eso exactamente su "loop" no lo es. Se ejecuta una vez y termina.
Un loop de verdad añade dos pasos obligatorios después de la salida:
El loop de seis pasos — lo que separa un loop de un disparo único
- 1
Fijar un objetivo
Define la meta con un criterio de aceptación medible. 'Mejorar el panel' no pasa esta prueba. 'Reducir el tiempo de carga inicial un 30 % sin romper el componente de filtros' sí la pasa. Sin una condición de parada concreta, el loop corre para siempre o termina de forma arbitraria — ambos son fallos. - 2
Hacer un plan
El agente descompone el objetivo en pasos discretos y ejecutables con salidas verificables en cada etapa. El plan no es fijo — se actualiza cuando Observar/Reflexionar realimentan nueva información. - 3
Ejecutar
El agente toma acciones: escribe código, llama APIs, edita archivos, ejecuta pruebas, lee mensajes de error. El harness determina a qué puede acceder. Aquí es donde se gasta la mayor parte del tiempo del desarrollador — pero es solo uno de seis pasos. - 4
Salida
El agente produce un resultado: un diff, un informe, el resultado de una prueba. Aquí es donde se detienen la mayoría de los 'loops' caseros. También es donde un loop de verdad apenas está empezando — la salida es la entrada de los dos pasos siguientes. - 5
Observar
Mira el resultado Y los pasos que lo produjeron — no solo la respuesta final. Un patrón habitual en producción: un segundo modelo independiente (el revisor) examina el trabajo contra la especificación original. El único trabajo del revisor es encontrar lo que el ejecutor pasó por alto. - 6
Reflexionar
Decide qué cambiar. Ajusta el objetivo, actualiza el plan y vuelve a empezar. El revisor empuja al ejecutor a iterar en lugar de cantar victoria pronto. Aquí es donde el loop se gana su nombre — sin Reflexionar, tienes una tubería, no un loop.
Qué hay dentro de un loop de producción
Un loop que sobrevive al contacto con el trabajo real tiene seis componentes. Que falte cualquiera de ellos suele ser donde ocurre el fallo.
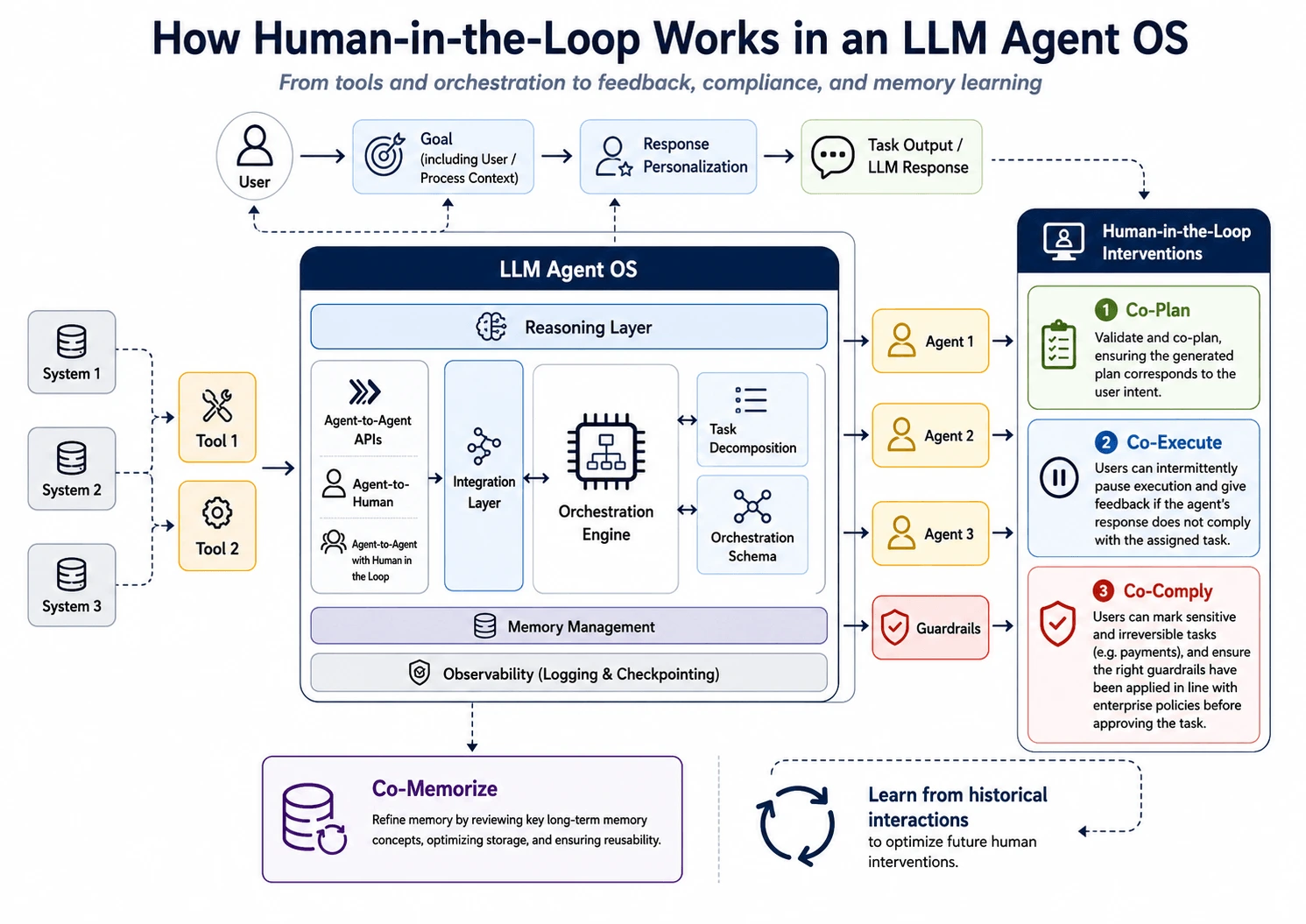
Las mismas seis partes mapeadas sobre un OS de agente completo: herramientas y orquestación alimentan a los agentes; las compuertas humanas (Co-Plan / Co-Execute / Co-Comply) y la memoria cierran el loop. Diagrama original de Mindber.
| Dimension | Componente | Qué hace | Sin él |
|---|---|---|---|
| Automatización | El latido. Algo despierta el loop: un calendario, un webhook, un evento de cambio de archivo. Sin esto, tienes un chat puntual. | Una sesión de chat, no un loop. Requiere que una persona inicie cada ejecución. | |
| Aislamiento del espacio de trabajo | Los agentes en paralelo necesitan copias de trabajo separadas (git worktrees, permisos acotados) para no sobrescribir los cambios de los demás. | Los agentes chocan a mitad de ejecución, produciendo trabajo corrupto o revertido. | |
| Skills | Experiencia codificada: plantillas de prompt reutilizables, procedimientos de verificación estándar, archivos de conocimiento de dominio. Cualquier cosa que se hace más de una vez debería convertirse en una skill — la próxima vez sale gratis. | Cada ciclo reinventa la rueda. No hay capitalización. El loop es caro y tonto. | |
| Conectores | APIs y herramientas que permiten al agente actuar en el mundo: git, correo, calendario, pagos, servidores de herramientas MCP. | El agente puede razonar pero no actuar. Un loop que solo puede escribir es un loop que no puede entregar. | |
| Sub-agentes (ejecutor + revisor) | Un agente ejecuta a velocidad (ejecutor). Un segundo agente independiente revisa contra la especificación (revisor). Ninguno tiene la última palabra por sí solo. | No hay compuerta interna de calidad. El loop entrega lo que produzca la primera pasada. | |
| Memoria | El loop escribe el progreso, los errores y las lecciones en un almacén persistente. Cada ejecución se apoya en la anterior. | Cada ciclo arranca desde cero. No hay capitalización. El sistema nunca se vuelve más inteligente. |
La regla más duradera de Steinberger: Cualquier cosa que hagas más de una vez debería convertirse en una skill, para que la próxima vez sea gratis. Un loop sin skills reutilizables dentro es solo un loop infinito envuelto alrededor de un desconocido. Las skills son el mecanismo de capitalización — sin ellas, alquilas inteligencia ejecución a ejecución en lugar de poseerla.
Las cuatro barandillas que hacen seguro dejarlo corriendo
Los componentes hacen que un loop funcione. Estas cuatro hacen seguro alejarse — la diferencia entre un sistema autónomo y un error caro que descubres en la siguiente factura de la tarjeta de crédito.
| Dimension | Barandilla | Qué previene | Cómo implementarla |
|---|---|---|---|
| Criterios de aceptación | Loops infinitos o terminaciones arbitrarias a mitad de tarea | Define 'terminado' en términos binarios antes de que el loop arranque. Medible, verificable, automatizado. Si no puedes describir 'terminado' en código, no inicies el loop. | |
| Límites de permisos | Agentes que se exceden de su alcance — borran archivos que no deberían tocar, fusionan sin revisión, disparan pagos | Mínimo privilegio. Decide qué puede cambiar, borrar, fusionar o pagar el agente antes de que se ejecute. La decisión de alcance es tuya; la aplicación es la barandilla. | |
| Compuerta humana | Errores irreversibles ejecutados a velocidad de máquina | Para llamadas sensibles o irreversibles (salida de dinero, merges a producción, cambios de esquema), el loop se pausa y deriva a una persona. No es opcional para operaciones de alto riesgo. | |
| Observabilidad | Fallos silenciosos, errores irrastreables, coste desbocado | Cada paso debe ser auditable. Ajustas un loop observando dónde se rompe — no adivinando. Logs, trazas de pasos y medidores de presupuesto no son opcionales. |
La parte honesta: lo que el ciclo de hype omite
Las personas más cercanas a este trabajo son las más cautelosas con él. Eso vale la pena tenerlo en cuenta.
Addy Osmani, que escribió el ensayo canónico, se declara abiertamente escéptico y subraya que es pronto — y que los costes de tokens oscilan enormemente según si eres "rico o pobre en tokens". Un loop sin límites puede quemar una fortuna en silencio mientras parece que avanza.
La verdad de fondo sobre el despliegue de agentes
~17%
de las organizaciones ha desplegado agentes de verdad
Gartner Hype Cycle 2026
Pico
IA agéntica en la curva de expectativas infladas de Gartner
Gartner Hype Cycle for AI, 2026
48h
Ventana máxima de valor para demos de agentes de respuesta rápida
Análisis editorial de Mindber
Steinberger traza una línea clara entre lo que funciona ahora y lo que no:
Funciona hoy — probado en producción:
- Varios agentes resolviendo issues en paralelo, con una persona revisando en el merge
- Tuberías acotadas y verificables: subidas de dependencias, codemods, arreglos de pruebas inestables
- Tareas donde "terminado" tiene una señal binaria y automatizada (las pruebas pasan / el diff está limpio / el endpoint devuelve 200)
Todavía no funciona — la admisión honesta:
- "Idea entra, producto sale" sin una persona sosteniendo la visión
- Comprometerse de antemano a un estado final fijo y automatizar por completo el camino hacia él — eso es waterfall con pasos extra
- El buen software todavía se descubre mediante iteración, no se declara por adelantado
La advertencia de Gartner: El pico de expectativas infladas no significa que la tecnología sea falsa. Significa que las demos van muy por delante de los despliegues, según el Gartner Hype Cycle for Artificial Intelligence. Source: Gartner Hype Cycle for Artificial Intelligence, 2026, Jun 17, 2026 Aproximadamente el 83 % de las organizaciones no ha desplegado agentes en absoluto. La brecha entre lo que se muestra en conferencias y lo que corre en producción es real, ancha y se cierra más despacio de lo que sugiere el hype.
Ver también: El verdadero coste de las herramientas de IA en 2026 — las cuentas de coste de tokens detrás de "rico vs. pobre en tokens".
Cuándo construir un loop — y cuándo no
Una pregunta determina la respuesta: ¿el trabajo se repite, y "terminado" es objetivamente medible?
¿Deberías construir un loop?
Construye el loop
- Subidas de dependencias y codemods
- Ciclos de detección y arreglo de pruebas inestables
- Tuberías de contenido o datos programadas
- Automatización de revisión de código en PRs
- Pruebas de regresión entre despliegues
Solo escribe el prompt
- Análisis o investigación de un solo uso
- Migración o mudanza de datos puntual
- Exploración inicial de una base de código
- Investigación ad hoc sin patrón de repetición
No se lo entregues a un loop
- 'Idear una mejor estrategia de producto'
- Dirección creativa abierta
- Decisiones que requieren contexto de negocio que un loop no puede sostener
- Trabajo sin una señal de éxito medible
La realidad de arranque para constructores con presupuesto ajustado
Para constructores en solitario y equipos pequeños — especialmente en todo el Sudeste Asiático, donde la mayoría de los constructores no son "ricos en tokens" — la disciplina de costes importa más que la ambición. El Mindber Innovation Index rastrea específicamente la eficiencia de coste de las herramientas: con cuánta gracia maneja cada herramienta las restricciones de recursos sin sacrificar la calidad de salida.
Tres reglas evitan que un loop se convierta en un pozo de dinero:
-
Limita un presupuesto de tokens por ejecución antes de alejarte. No un límite vago — un número estricto, aplicado en la capa de código. Los presupuestos de tokens son el límite de tarjeta de crédito de tu loop. Si el límite no está en el código, no existe.
-
Empieza con una tarea acotada y verificable antes de encadenar varias. La complejidad se acumula rápido. Gánate la confianza en la versión simple antes de añadir etapas. El Mindber Functionality Score para Claude Code y herramientas comparables mide precisamente esto: ¿qué tan bien maneja la herramienta las barandillas de presupuesto y los modos de fallo elegantes en la práctica?
-
Detente automáticamente cuando el mismo error, un diff vacío o una prueba fallida se repitan N veces seguidas. Un loop que no puede detenerse a sí mismo no es autónomo — solo es caro. La regla de parada no es opcional.
El principio de Steinberger: Un loop que se compromete de antemano a un estado final fijo y automatiza por completo el camino hacia él ha reinventado en silencio el waterfall. El software todavía se descubre mediante iteración — no se declara por adelantado. Construye puntos de control. Mantén a las personas en el loop de decisión para cualquier cosa irreversible.
Qué significa esto para la selección de herramientas
No todos los runtimes de agentes soportan los patrones de loop por igual. El Mindber Innovation Index rastrea qué herramientas de la categoría de agentes de programación con IA han lanzado infraestructura de loop nativa — ejecución programada, delegación a sub-agentes, persistencia de estado, límites de presupuesto — frente a cuáles te obligan a construirlo todo desde cero.
Herramientas como Claude Code, Codex de OpenAI, Cursor y OpenClaw vienen con grados variables de esta infraestructura integrada. La lógica del loop se sitúa alrededor del agente — así que gran parte de ella la construyes tú independientemente de la herramienta que elijas. El Mindber Functionality Score captura cuánto andamiaje provee cada herramienta de fábrica frente a cuánto te corresponde a ti. Esa diferencia importa más para equipos pequeños que no pueden permitirse reconstruir las mismas cañerías dos veces.
Dónde profundizar:
- Página de producto de Claude Code — el Mindber Functionality Score y el desglose de capacidades
- Categoría de agentes de programación con IA — todas las herramientas rastreadas en el espacio, clasificadas
- Compara herramientas de agentes lado a lado — frente a frente en arquitectura y precio
- Rankings de Mindber — la tabla en vivo por adopción rastreada
- Manus vs Claude Cowork (2026) — cómo difieren en la práctica las arquitecturas de agentes
- La epidemia de software de IA sin usar (2026) — por qué la mayoría de los agentes desplegados quedan sin uso
- El verdadero coste de las herramientas de IA (2026) — las cuentas de tokens detrás de la economía de los loops
¿El prompt engineering está muerto por culpa del loop engineering?
No. El punto de apalancamiento se movió, no la habilidad. Los prompts aún hay que escribirlos — la diferencia es que ahora un loop es lo que los llama según un calendario, no un desarrollador haciéndolo a mano. La calidad del prompt sigue determinando la calidad de la salida dentro de cada loop. Lo que cambió es quién (o qué) decide cuándo llamar al prompt.
¿Cuál es la diferencia entre harness engineering y loop engineering?
Un harness equipa una sola ejecución del agente con herramientas, permisos y señales de retroalimentación (ejecuta el código, lee el error, verifica la salida). Un loop es la capa por encima: mantiene al agente ejecutándose a lo largo de muchas ejecuciones, genera sub-agentes, verifica resultados, persiste el estado y decide qué hacer a continuación. Harness = una ejecución equipada. Loop = el sistema que sigue programando, ejecutando y capitalizando conocimiento a lo largo de muchas ejecuciones.
¿Necesito loop engineering para un proyecto pequeño o en solitario?
Normalmente no. Si el trabajo es único o depende mucho del criterio, un buen prompt le gana a un loop cada vez. Los loops compensan específicamente en trabajo repetitivo con una definición binaria de éxito. La mayoría de las tareas de proyectos pequeños no cumple ese listón — y el sobrecoste de construir un loop sobre algo que corre dos veces es una pérdida neta.
¿Qué herramientas soportan loop engineering de forma nativa hoy?
Los agentes de programación construidos en torno a la ejecución iterativa — Claude Code, Codex de OpenAI, Cursor y OpenClaw entre ellos. La lógica del loop se sitúa en gran medida alrededor del agente y no dentro de él, así que gran parte la construyes tú independientemente de la herramienta. Busca herramientas que provean: ejecución programada, delegación a sub-agentes, persistencia de estado integrada y condiciones de parada configurables. La categoría de agentes de programación con IA de Mindber rastrea la cobertura de infraestructura actual por herramienta.
¿Cuál es el mayor riesgo del loop engineering?
Sobrecostes y loops desbocados. Sin criterios de aceptación, un límite de presupuesto y una regla de parada estricta, un loop puede quemar tokens indefinidamente mientras aparenta ser productivo. El segundo riesgo: la sobreingeniería. Construir un loop para una tarea que corre una o dos veces es desperdicio, no automatización. La disciplina está en saber en qué cubo cae tu trabajo antes de empezar a construir.
¿Quién acuñó el término 'loop engineering'?
El término cristalizó en junio de 2026 en torno a declaraciones públicas de Peter Steinberger (creador de OpenClaw, ahora en OpenAI) y Boris Cherny (responsable de Claude Code en Anthropic), con Addy Osmani de Google escribiendo el ensayo de referencia que definió el concepto y su relación por capas con el prompt engineering, el context engineering y el harness engineering.
¿En qué se diferencia el loop engineering de la automatización tradicional?
La automatización tradicional sigue scripts fijos contra sistemas deterministas. El loop engineering usa agentes de IA — así que el camino de ejecución es adaptativo, las acciones se dirigen mediante lenguaje natural y el sistema puede manejar situaciones que el programador original no anticipó. La estructura del loop (objetivo → actuar → observar → reflexionar → repetir) está tomada de la teoría de control clásica, pero el agente que vive dentro es no determinista y puede generalizar. El equilibrio: más capaz, más difícil de predecir, más caro de ejecutar.
¿Qué debería 'loopear' primero? Un punto de partida práctico para 2026.
La recomendación de Steinberger: empieza con subidas de dependencias, codemods o arreglos de pruebas inestables. Estas tareas son acotadas, tienen una señal binaria de éxito/fracaso (CI en verde / diff limpio), corren sin criterio humano y se repiten según un calendario. Una vez que existe un loop funcional para una de ellas, el patrón se transfiere a tareas más complejas — pero solo después de que la versión simple haya corrido de forma fiable en producción durante unas semanas. El patrón se transfiere; la confianza hay que ganársela de forma incremental.
Fuentes y metodología editorial
Este artículo sintetiza declaraciones públicas primarias, ensayos publicados e investigación de analistas citados en línea. El equipo editorial de Mindber etiqueta los hechos establecidos por separado de las afirmaciones especulativas o en etapa temprana. No se realizó ninguna evaluación directa de implementaciones de loop específicas — esto es análisis editorial de información pública procedente de las fuentes primarias citadas.
- [1]El planteamiento público de Peter Steinberger sobre el loop engineering y el diseño de sistemas que prompteen a los agentesPublic post, June 2026 — 2026-06-07
- [2]Boris Cherny sobre escribir loops en lugar de promptear los modelos directamenteAnthropic / Claude Code — public statements — 2026-06-07
- [3]El ensayo de referencia de Addy Osmani que define las capas del loop engineering y expresa escepticismo sobre las afirmaciones en etapa tempranaAddy Osmani — public writing — 2026-06-17
- [4]La ubicación de Gartner de la IA agéntica en el pico de expectativas infladas; ~17 % de las organizaciones ha desplegado agentesGartner Hype Cycle for Artificial Intelligence, 2026 — 2026-06-17
Profundiza en la arquitectura de agentes
Manus vs Claude Cowork (2026): agente en la nube vs. de escritorio
Arquitectura, precio y cumplimiento — la comparación definitiva para constructores que eligen entre agentes de IA alojados y locales primero.
El verdadero coste de las herramientas de IA en 2026
Precio de tokens, costes ocultos y la división entre ricos y pobres en tokens que determina qué patrones de loop son financieramente viables para tu equipo.
Share this article
Aviso legal
Esta publicación constituye comentario editorial sobre información disponible públicamente y no constituye asesoramiento financiero, legal, de inversión ni profesional. Los nombres de productos, marcas comerciales y marcas registradas mencionados pertenecen a sus respectivos propietarios; su aparición no implica respaldo ni afiliación. El análisis de Mindber refleja juicio editorial basado en señales públicas y puede cambiar sin previo aviso. Las puntuaciones no son recomendaciones de compra, venta o mantenimiento. No existe relación comercial entre Mindber y los proveedores evaluados salvo que se indique por escrito. Esta publicación se rige por las leyes de Malasia. Cualquier disputa derivada de esta publicación o relacionada con ella se someterá a la jurisdicción exclusiva de los tribunales de Malasia.
Generado por IA · Este informe fue generado con modelos de lenguaje de IA entrenados con datos disponibles públicamente. Refleja análisis editorial en el momento de generación y no es resultado de pruebas prácticas del producto, verificación independiente por un analista humano ni respaldo comercial. Todas las puntuaciones, evaluaciones y afirmaciones se derivan de señales indexadas por Mindber en el momento de generación y pueden cambiar sin previo aviso. Mindber y sus operadores no garantizan exactitud, integridad ni idoneidad para ningún propósito de toma de decisiones comerciales. Este informe es solo informativo.