Loop Engineering: ทำไมวิศวกรชั้นนำเลิกป้อนพรอมต์ให้ AI
คู่มืออัปเดต อ่าน 8 นาที
ออกแบบระบบที่ป้อนพรอมต์ให้ AI agent ของคุณแทนการเขียนพรอมต์เอง สิ่งที่ใช้ได้จริงในงานโปรดักชันวันนี้ สิ่งที่ยังไม่ได้ และเมื่อใดควรข้ามไปเลย

ตรวจสอบล่าสุด: 2026-06-17 ข้อความที่อ้างถึง Peter Steinberger, Boris Cherny และ Addy Osmani มาจากโพสต์และบทความสาธารณะของพวกเขา ณ วันที่นี้ วงการนี้เคลื่อนไหวเร็วมาก — ตรวจสอบแหล่งที่มาที่ลิงก์ไว้เพื่อจุดยืนล่าสุด
โดย Frankie C. · นักวิจัยตลาดอาวุโส Mindber ติดตามเครื่องมือ AI/SaaS กว่า 500 ตัวในตลาด SEA ผ่านระเบียบวิธี Mindber Innovation Index
ในวันที่ 7 มิถุนายน 2026 นักพัฒนาชื่อ Peter Steinberger ได้โพสต์สองประโยคที่ดึงยอดวิวหลายล้านและเปิดข้อถกเถียงที่วงการ AI-coding คิดว่าได้ข้อสรุปแล้วขึ้นมาใหม่ ประเด็นของเขา: เลิกพิมพ์พรอมต์ใส่ coding agent ของคุณ สร้างระบบที่ป้อนพรอมต์ให้คุณแทน ก่อนหน้านั้นไม่กี่วัน Boris Cherny — ผู้ดูแล Claude Code ที่ Anthropic — ได้สังเกตเห็นสิ่งเดียวกันจากภายใน: เขาไม่ป้อนพรอมต์ให้โมเดลอีกต่อไป เขาเขียน loop และ loop เป็นตัวป้อนพรอมต์
สำหรับภูมิหลังว่า Mindber ให้คะแนนเครื่องมือที่เกี่ยวข้องอย่างไร ดูที่ หมวด AI coding agents และ ระเบียบวิธีเบื้องหลัง Mindber Innovation Index
โพสต์ที่เปิดข้อถกเถียงขึ้นมาใหม่: Peter Steinberger ว่าด้วยการสร้าง loop แทนการพิมพ์พรอมต์ ที่มา: Peter Steinberger บน X, มิถุนายน 2026
ตอนนี้แนวคิดนั้นมีชื่อแล้ว: loop engineering การรายงานข่าวส่วนใหญ่นับแต่นั้นเต็มไปด้วยความตื่นเต้นเกินจริง นี่คือเวอร์ชันที่ปลด-hype ออกแล้ว — มันคืออะไร อะไรใช้ได้จริงในงานโปรดักชันวันนี้ อะไรที่ยังไม่ได้ และเมื่อใดที่ไม่ควรสร้าง loop เลย
Loop engineering คืออะไร?
Loop engineering คือการปฏิบัติในการออกแบบระบบที่รัน AI agent เป็นรอบ ๆ — ตั้งเป้าหมาย ลงมือทำ สังเกตผลลัพธ์ สะท้อนคิด แล้วทำซ้ำ — จนกว่าจะบรรลุเป้าหมายหรือระบบส่งการควบคุมกลับให้มนุษย์
การเปลี่ยนแปลงนี้เกี่ยวกับว่าใครเป็นคนป้อนพรอมต์ แทนที่นักพัฒนาจะคอยบังคับ agent ทีละเทิร์น พวกเขาสร้าง loop ที่คอยบังคับมันแทน Steinberger (ผู้สร้างโปรเจกต์ agent โอเพนซอร์ส OpenClaw ปัจจุบันอยู่ที่ OpenAI) อธิบายงานนี้ว่าเป็นการออกแบบ "loop ที่ป้อนพรอมต์ให้ agent ของคุณ" Addy Osmani วิศวกร Google ที่ บทความว่าด้วย loop engineering ของเขากลายเป็นเอกสารอ้างอิงหลัก อธิบาย loop ว่าเป็นเป้าหมายแบบเรียกซ้ำ: นิยามจุดประสงค์ แล้ววนซ้ำจนเสร็จ
บททดสอบหนึ่งบรรทัด: หากคุณพบว่าตัวเองรันพรอมต์เดิมซ้ำ ๆ — ด้วยบริบทที่ต่างกันเล็กน้อยในแต่ละครั้ง — แสดงว่าคุณมี loop แบบทำมืออยู่แล้ว loop engineering คือสิ่งที่คุณสร้างขึ้นเพื่อให้เลิกทำสิ่งนั้นด้วยมือ
Loop engineering อยู่ตรงไหน: สี่ชั้นของสแต็ก
Loop engineering ไม่ได้โผล่ขึ้นมาจากที่ไหน มันคือยอดบนสุดของสแต็กที่เติบโตขึ้นเมื่อ agent มีความสามารถมากขึ้น แต่ละชั้นตอบคำถามที่แตกต่างกันโดยพื้นฐาน
สี่ชั้นของวิศวกรรม AI — แต่ละชั้นต่อยอดจากชั้นก่อนหน้า
- 1
Prompt Engineering
ระยะเริ่มต้นคำถามที่มันตอบ: ฉันจะเรียบเรียงคำขอหนึ่งคำขออย่างไร? สิ่งที่คุณควบคุม: ถ้อยคำของอินพุตเดียว แกนหลักคือการแสดงออกของมนุษย์ที่แม่นยำ — การถามโมเดลให้ชัดเจนพอที่จะยกระดับความเข้าใจในพรอมต์เดียว - 2
Context / Workflow Engineering
ระยะกลางคำถาม: ฉันจะร้อยเรียงขั้นตอนและป้อนภูมิหลังอย่างไร? สิ่งที่คุณควบคุม: ข้อมูลและลำดับที่ agent เห็น ห่วงโซ่ตรรกะแบบกำหนดแน่นอนบวกกับบริบทโปรเจกต์ที่เต็มขึ้นช่วยยกระดับความเข้าใจของโมเดลต่องานใหญ่ที่มีหลายขั้นตอน - 3
Harness Engineering
ชั้น runtimeคำถาม: ฉันจะติดตั้งอุปกรณ์ให้การรัน agent หนึ่งครั้งอย่างไร? สิ่งที่คุณควบคุม: เครื่องมือ สิทธิ์ และสัญญาณที่ตรวจสอบได้ — รันโค้ด อ่าน error คุณสร้างสภาพแวดล้อมการรันและมอบเครื่องมือ การเข้าถึง และสัญญาณการรันที่ตรวจสอบได้ที่ถูกต้องให้ agent - 4
Loop Engineering
พรมแดนปัจจุบันคำถาม: ฉันจะทำให้ agent รันและพัฒนาตัวเองต่อไปได้อย่างไร? สิ่งที่คุณควบคุม: ระบบที่ทริกเกอร์ มอบหมาย ตรวจสอบ คงสถานะไว้ และตัดสินใจว่าจะทำอะไรต่อ — loop แบบปิดที่ให้ agent แก้ไขตัวเองแทนที่จะรอให้มนุษย์มาตรวจ
วิธีที่ชัดเจนในการจับความแตกต่าง: harness ติดตั้งอุปกรณ์ให้การรันครั้งเดียว; loop คือสิ่งที่คอยกระทุ้ง agent ตามตารางเวลา สร้างผู้ช่วย ป้อนข้อมูลให้ตัวเองข้ามการรันหลายครั้ง และทบทวีสิ่งที่มันเรียนรู้
ข้อถกเถียงส่วนใหญ่เรื่อง "การป้อนพรอมต์ vs วิศวกรรม" ยุบสแต็กทั้งหมดนี้ลงเป็นสิ่งเดียว มันไม่ใช่สิ่งเดียวกัน และการเหมารวมมันก่อให้เกิดการเลือกใช้เครื่องมือผิดสำหรับงานในทุกชั้น
กายวิภาคของ loop ที่แท้จริง
โมเดลความคิดของคนส่วนใหญ่เกี่ยวกับ agent: Goal → Plan → Execute → Output นั่นคือจุดที่พวกเขาหยุด — และนั่นคือเหตุผลที่ "loop" ของพวกเขาไม่ใช่ loop มันรันครั้งเดียวแล้วเลิก
loop ที่แท้จริงเพิ่มสองขั้นตอนบังคับ หลังจาก output:
loop หกขั้นตอน — สิ่งที่แยก loop ออกจากการรันครั้งเดียว
- 1
ตั้งเป้าหมาย
นิยามเป้าด้วยเกณฑ์การยอมรับที่วัดผลได้ 'ปรับปรุงแดชบอร์ด' ไม่ผ่านบททดสอบนี้ 'ลดเวลาโหลดเริ่มต้นลง 30% โดยไม่ทำให้คอมโพเนนต์ฟิลเตอร์พัง' ผ่าน หากไม่มีเงื่อนไขหยุดที่เป็นรูปธรรม loop จะรันไปตลอดกาลหรือเลิกแบบไร้เหตุผล — ทั้งคู่คือความล้มเหลว - 2
วางแผน
agent แตกเป้าหมายออกเป็นขั้นตอนที่แยกย่อยและทำได้ พร้อม output ที่ตรวจสอบได้ในแต่ละช่วง แผนไม่ตายตัว — มันอัปเดตเมื่อ Observe/Reflect ป้อนข้อมูลใหม่กลับเข้ามา - 3
ดำเนินการ
agent ลงมือ: เขียนโค้ด เรียก API แก้ไฟล์ รันเทสต์ อ่านข้อความ error harness กำหนดว่ามันเข้าถึงอะไรได้ นี่คือจุดที่นักพัฒนาใช้เวลาส่วนใหญ่ — แต่มันเป็นเพียงหนึ่งในหกขั้นตอน - 4
ผลลัพธ์
agent สร้างผลลัพธ์: diff รายงาน ผลของเทสต์ นี่คือจุดที่ 'loop' แบบ DIY ส่วนใหญ่หยุด มันยังเป็นจุดที่ loop ที่แท้จริงเพิ่งจะเริ่มต้น — output คืออินพุตของสองขั้นตอนถัดไป - 5
สังเกต
ดูทั้งผลลัพธ์และขั้นตอนที่ผลิตมัน — ไม่ใช่แค่คำตอบสุดท้าย รูปแบบที่พบบ่อยในงานโปรดักชัน: โมเดลที่สองที่เป็นอิสระ (ผู้ตรวจ) ทบทวนงานเทียบกับสเปกตั้งต้น หน้าที่เดียวของผู้ตรวจคือหาสิ่งที่ผู้สร้างพลาดไป - 6
สะท้อนคิด
ตัดสินใจว่าจะเปลี่ยนอะไร ปรับเป้าหมาย อัปเดตแผน แล้วลองใหม่อีกครั้ง ผู้ตรวจผลักให้ผู้สร้างวนซ้ำแทนที่จะประกาศชัยชนะก่อนเวลา นี่คือจุดที่ loop สมชื่อ — หากไม่มี Reflect คุณก็มีแค่ pipeline ไม่ใช่ loop
ภายใน loop ของงานโปรดักชันมีอะไร
loop ที่รอดพ้นจากการปะทะกับงานจริงมีหกองค์ประกอบ การขาดองค์ประกอบใดองค์ประกอบหนึ่งมักเป็นจุดที่ความล้มเหลวเกิดขึ้น
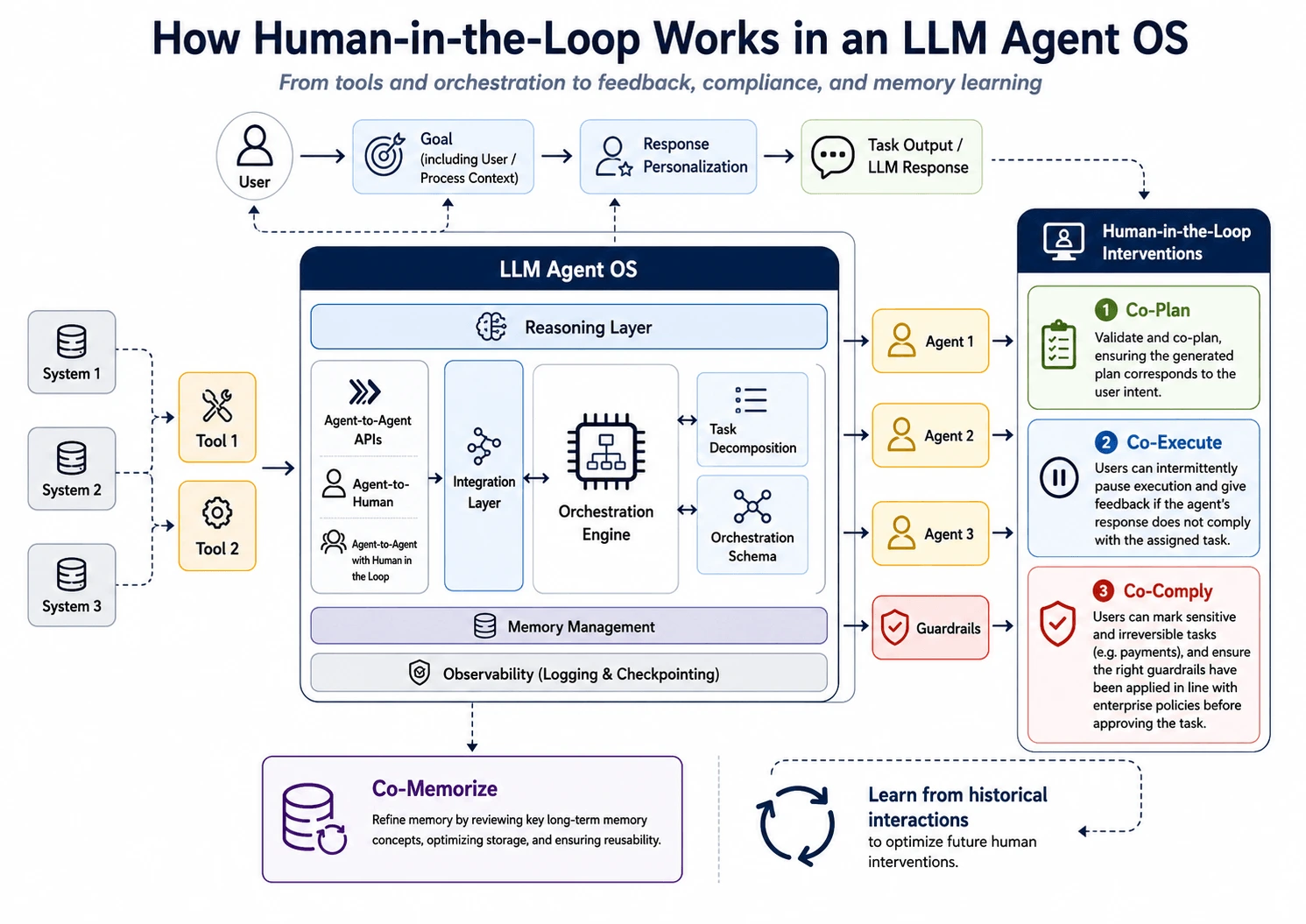
หกองค์ประกอบเดียวกันแมปลงบนระบบปฏิบัติการ agent เต็มรูปแบบ: เครื่องมือและออร์เคสเตรชันป้อนให้ agent; ประตูมนุษย์ (Co-Plan / Co-Execute / Co-Comply) และ memory ปิด loop ไดอะแกรมต้นฉบับของ Mindber
| Dimension | องค์ประกอบ | หน้าที่ | หากขาดมันไป |
|---|---|---|---|
| Automation | หัวใจที่เต้น บางอย่างปลุก loop: ตารางเวลา webhook เหตุการณ์ไฟล์เปลี่ยน หากไม่มีมัน คุณก็มีแค่แชตครั้งเดียว | เซสชันแชต ไม่ใช่ loop ต้องมีมนุษย์เริ่มทุกการรัน | |
| การแยกพื้นที่ทำงาน | agent ที่รันขนานกันต้องการสำเนางานแยกกัน (git worktrees, สิทธิ์ที่จำกัดขอบเขต) เพื่อไม่ให้เขียนทับการเปลี่ยนแปลงของกันและกัน | agent ชนกันกลางการรัน ผลิตงานที่เสียหายหรือถูกย้อนกลับ | |
| Skills | ประสบการณ์ที่ถูกบันทึกเป็นโค้ด: เทมเพลตพรอมต์ที่ใช้ซ้ำได้ ขั้นตอนการตรวจสอบมาตรฐาน ไฟล์ความรู้เฉพาะทาง สิ่งใดที่ทำมากกว่าหนึ่งครั้งควรกลายเป็น skill — ครั้งต่อไปจะฟรี | ทุกรอบประดิษฐ์ล้อใหม่ ไม่มีการทบทวี loop แพงและโง่ | |
| Connectors | API และเครื่องมือที่ให้ agent ลงมือทำในโลกจริง: git, อีเมล, ปฏิทิน, การชำระเงิน, เซิร์ฟเวอร์เครื่องมือ MCP | agent ให้เหตุผลได้แต่ลงมือทำไม่ได้ loop ที่ทำได้แค่เขียนคือ loop ที่ส่งมอบไม่ได้ | |
| Sub-agents (ผู้สร้าง + ผู้ตรวจ) | agent หนึ่งดำเนินการด้วยความเร็ว (ผู้สร้าง) agent อิสระตัวที่สองทบทวนเทียบกับสเปก (ผู้ตรวจ) ไม่มีตัวใดมีคำตัดสินสุดท้ายโดยลำพัง | ไม่มีประตูคุณภาพภายใน loop ส่งมอบสิ่งที่รอบแรกผลิตออกมาไม่ว่ามันคืออะไร | |
| Memory | loop เขียนความคืบหน้า error และบทเรียนลงในที่เก็บถาวร การรันแต่ละครั้งต่อยอดจากครั้งก่อน | ทุกรอบเริ่มจากศูนย์ ไม่มีการทบทวี ระบบไม่เคยฉลาดขึ้น |
กฎที่ทนทานที่สุดของ Steinberger: สิ่งใดที่คุณทำมากกว่าหนึ่งครั้งควรกลายเป็น skill เพื่อให้ครั้งต่อไปฟรี loop ที่ไม่มี skill ที่ใช้ซ้ำได้อยู่ภายในก็เป็นแค่ loop ไม่รู้จบที่ห่อหุ้มคนแปลกหน้าเอาไว้ Skills คือกลไกการทบทวี — หากไม่มีมัน คุณก็เช่าความฉลาดทีละการรันแทนที่จะเป็นเจ้าของมัน
สี่ราวกั้นที่ทำให้ปลอดภัยพอจะปล่อยให้รันต่อไป
องค์ประกอบทำให้ loop รัน สี่สิ่งนี้ทำให้ปลอดภัยพอจะเดินจากไป — ความต่างระหว่างระบบอัตโนมัติกับความผิดพลาดราคาแพงที่คุณค้นพบจากบิลบัตรเครดิตใบถัดไป
| Dimension | ราวกั้น | สิ่งที่มันป้องกัน | วิธีนำไปใช้ |
|---|---|---|---|
| เกณฑ์การยอมรับ | loop ไม่รู้จบหรือการเลิกแบบไร้เหตุผลกลางงาน | นิยาม 'เสร็จ' ในรูปแบบไบนารีก่อน loop เริ่ม วัดผลได้ ตรวจสอบได้ อัตโนมัติ หากคุณอธิบาย 'เสร็จ' เป็นโค้ดไม่ได้ ก็อย่าเริ่ม loop | |
| ขอบเขตสิทธิ์ | agent ก้าวเกินขอบเขต — ลบไฟล์ที่ไม่ควรแตะ merge โดยไม่ตรวจ ทริกเกอร์การชำระเงิน | ให้สิทธิ์น้อยที่สุด ตัดสินว่า agent อาจเปลี่ยน ลบ merge หรือจ่ายอะไรได้ก่อนมันรัน การตัดสินขอบเขตเป็นของคุณ; การบังคับใช้คือราวกั้น | |
| ประตูมนุษย์ | ความผิดพลาดที่ย้อนกลับไม่ได้ซึ่งถูกดำเนินการด้วยความเร็วเครื่องจักร | สำหรับการกระทำที่อ่อนไหวหรือย้อนกลับไม่ได้ (จ่ายเงินออก merge เข้าโปรดักชัน เปลี่ยน schema) loop จะหยุดและส่งต่อให้มนุษย์ ไม่ใช่ทางเลือกสำหรับการดำเนินการเดิมพันสูง | |
| การสังเกตการณ์ | ความล้มเหลวที่เงียบงัน error ที่ตามรอยไม่ได้ ต้นทุนที่พุ่งพรวด | ทุกขั้นตอนต้องตรวจสอบย้อนหลังได้ คุณปรับจูน loop ด้วยการเฝ้าดูว่ามันพังตรงไหน — ไม่ใช่ด้วยการเดา Log, การติดตามขั้นตอน และมิเตอร์งบประมาณไม่ใช่ทางเลือก |
ส่วนที่ซื่อสัตย์: สิ่งที่วงจร hype มองข้าม
คนที่ใกล้ชิดกับงานนี้ที่สุดคือคนที่ระมัดระวังกับมันมากที่สุด นั่นเป็นเรื่องที่ควรให้ความสนใจ
Addy Osmani ผู้เขียนบทความต้นแบบ เรียกตัวเองอย่างเปิดเผยว่า ขี้สงสัย และย้ำว่ามันยังเป็นช่วงเริ่มต้น — และต้นทุน token เหวี่ยงไปมาอย่างมากขึ้นอยู่กับว่าคุณ "token rich หรือ token poor" loop ที่ไม่มีขอบเขตสามารถเผาเงินเป็นกองอย่างเงียบ ๆ ในขณะที่ดูเหมือนกำลังคืบหน้า
ความจริงพื้นฐานเรื่องการ deploy agent
~17%
ขององค์กรที่ได้ deploy agent จริง
Gartner Hype Cycle 2026
จุดสูงสุด
Agentic AI บนเส้นโค้งความคาดหวังที่พองเกินจริงของ Gartner
Gartner Hype Cycle for AI, 2026
48 ชม.
หน้าต่างคุณค่าสูงสุดสำหรับเดโม agent ตอบสนองรวดเร็ว
Mindber editorial analysis
Steinberger ขีดเส้นชัดเจนระหว่างสิ่งที่ใช้ได้ตอนนี้กับสิ่งที่ยังไม่ได้:
ใช้ได้วันนี้ — พิสูจน์แล้วในงานโปรดักชัน:
- agent หลายตัวรัน issue ขนานกัน โดยมีมนุษย์ตรวจตอน merge
- pipeline ที่แคบและตรวจสอบได้: การอัป dependency, codemods, การแก้เทสต์ที่ไม่เสถียร
- งานที่ "เสร็จ" มีสัญญาณไบนารีอัตโนมัติ (เทสต์ผ่าน / diff สะอาด / endpoint คืนค่า 200)
ยังไม่ได้ผล — การยอมรับอย่างซื่อสัตย์:
- "ใส่ไอเดียเข้าไป ได้ผลิตภัณฑ์ออกมา" โดยไม่มีมนุษย์ถือวิสัยทัศน์ไว้
- การผูกมัดตัวเองไว้กับสถานะปลายทางที่ตายตัวล่วงหน้าและทำเส้นทางสู่มันให้อัตโนมัติเต็มรูปแบบ — นั่นคือ waterfall ที่มีขั้นตอนเพิ่ม
- ซอฟต์แวร์ที่ดียังคงถูกค้นพบผ่านการวนซ้ำ ไม่ใช่ประกาศไว้ล่วงหน้า
ข้อแม้ของ Gartner: จุดสูงสุดของความคาดหวังที่พองเกินจริงไม่ได้หมายความว่าเทคโนโลยีนั้นปลอม มันหมายความว่าเดโมล้ำหน้าการ deploy ไปไกล ตาม Gartner Hype Cycle for Artificial Intelligence Source: Gartner Hype Cycle for Artificial Intelligence, 2026, Jun 17, 2026 ราว 83% ขององค์กรยังไม่ได้ deploy agent เลย ช่องว่างระหว่างสิ่งที่แสดงในงานประชุมกับสิ่งที่รันจริงในโปรดักชันนั้นมีจริง กว้าง และหุบช้ากว่าที่ hype บอกไว้
ดูเพิ่มเติม: ต้นทุนที่แท้จริงของเครื่องมือ AI ในปี 2026 — คณิตศาสตร์ต้นทุน token เบื้องหลัง "token rich vs. token poor"
เมื่อใดควรสร้าง loop — และเมื่อใดไม่ควร
คำถามเดียวกำหนดคำตอบ: งานนั้นทำซ้ำหรือไม่ และ "เสร็จ" วัดผลได้อย่างเป็นกลางหรือไม่?
คุณควรสร้าง loop หรือไม่?
สร้าง loop
- การอัป dependency และ codemods
- การตรวจจับและแก้เทสต์ที่ไม่เสถียร
- pipeline เนื้อหาหรือข้อมูลตามตารางเวลา
- การทำ code review อัตโนมัติบน PR
- การทดสอบ regression ข้ามการ deploy
แค่เขียนพรอมต์ก็พอ
- การวิเคราะห์หรือสืบสวนใช้ครั้งเดียว
- การย้ายข้อมูลหรือ migration ครั้งเดียว
- การสำรวจ codebase รอบแรก
- การวิจัยเฉพาะกิจที่ไม่มีรูปแบบทำซ้ำ
อย่ายกให้ loop
- 'คิดกลยุทธ์ผลิตภัณฑ์ที่ดีกว่าออกมา'
- ทิศทางสร้างสรรค์ที่เปิดกว้าง
- การตัดสินใจที่ต้องใช้บริบทธุรกิจที่ loop ถือไว้ไม่ได้
- งานที่ไม่มีสัญญาณความสำเร็จที่วัดได้
ความจริงเรื่อง bootstrap สำหรับนักสร้างที่ใส่ใจต้นทุน
สำหรับนักสร้างเดี่ยวและทีมเล็ก — โดยเฉพาะทั่วเอเชียตะวันออกเฉียงใต้ ที่นักสร้างส่วนใหญ่ไม่ได้ "token rich" — วินัยด้านต้นทุนสำคัญกว่าความทะเยอทะยาน Mindber Innovation Index ติดตามประสิทธิภาพด้านต้นทุนของเครื่องมือโดยเฉพาะ: แต่ละเครื่องมือรับมือกับข้อจำกัดของทรัพยากรได้อย่างราบรื่นเพียงใดโดยไม่ลดทอนคุณภาพของผลลัพธ์
กฎสามข้อกัน loop ไม่ให้กลายเป็นหลุมเงิน:
-
จำกัดงบ token ต่อการรันก่อนเดินจากไป ไม่ใช่ขีดจำกัดคลุมเครือ — เป็นตัวเลขที่เด็ดขาด บังคับใช้ที่ชั้นโค้ด งบ token คือวงเงินบัตรเครดิตของ loop คุณ หากขีดจำกัดไม่อยู่ในโค้ด มันก็ไม่มีอยู่จริง
-
เริ่มจากงานเดียวที่แคบและตรวจสอบได้ก่อนร้อยหลายอย่างเข้าด้วยกัน ความซับซ้อนทบทวีอย่างรวดเร็ว สร้างความไว้ใจในเวอร์ชันง่าย ๆ ก่อนเพิ่มขั้นตอน Mindber Functionality Score สำหรับ Claude Code และเครื่องมือที่เทียบเคียงได้วัดสิ่งนี้โดยเฉพาะ: เครื่องมือรับมือกับราวกั้นงบประมาณและโหมดความล้มเหลวที่ราบรื่นได้ดีเพียงใดในทางปฏิบัติ?
-
หยุดอัตโนมัติเมื่อ error เดิม diff ว่างเปล่า หรือเทสต์ที่ไม่ผ่านเกิดซ้ำ N ครั้งติดต่อกัน loop ที่หยุดตัวเองไม่ได้ไม่ใช่อัตโนมัติ — มันแค่แพง กฎหยุดไม่ใช่ทางเลือก
หลักการของ Steinberger: loop ที่ผูกมัดตัวเองไว้กับสถานะปลายทางที่ตายตัวล่วงหน้าและทำเส้นทางสู่มันให้อัตโนมัติเต็มรูปแบบได้ประดิษฐ์ waterfall ขึ้นมาใหม่อย่างเงียบ ๆ ซอฟต์แวร์ยังคงถูกค้นพบผ่านการวนซ้ำ — ไม่ใช่ประกาศไว้ล่วงหน้า สร้างจุดตรวจไว้ คงมนุษย์ไว้ใน loop การตัดสินใจสำหรับสิ่งใดก็ตามที่ย้อนกลับไม่ได้
สิ่งนี้หมายความว่าอย่างไรต่อการเลือกเครื่องมือ
ไม่ใช่ทุก agent runtime ที่รองรับรูปแบบ loop ได้เท่ากัน Mindber Innovation Index ติดตามว่าเครื่องมือใดในหมวด AI coding agents ได้ส่งมอบโครงสร้างพื้นฐาน loop แบบ native — การรันตามตารางเวลา การมอบหมายให้ sub-agent การคงสถานะ การจำกัดงบประมาณ — เทียบกับเครื่องมือที่บังคับให้คุณสร้างทั้งหมดเองตั้งแต่ต้น
เครื่องมืออย่าง Claude Code, Codex ของ OpenAI, Cursor และ OpenClaw มาพร้อมกับโครงสร้างพื้นฐานนี้ในระดับที่แตกต่างกัน ตรรกะ loop ตั้งอยู่ รอบ ๆ agent — ซึ่งส่วนใหญ่คุณต้องสร้างเองไม่ว่าจะเลือกเครื่องมือใด Mindber Functionality Score จับว่าแต่ละเครื่องมือให้นั่งร้านมากแค่ไหนตั้งแต่แกะกล่อง เทียบกับที่คุณต้องเป็นเจ้าของเอง ส่วนต่างนั้นสำคัญที่สุดสำหรับทีมเล็กที่ไม่สามารถสร้างท่อประปาเดิมซ้ำสองรอบได้
ที่ไหนให้ขุดลึกกว่านี้:
- หน้าผลิตภัณฑ์ Claude Code — Mindber Functionality Score และการแยกย่อยความสามารถ
- หมวด AI coding agents — ทุกเครื่องมือที่ติดตามในวงการนี้ จัดอันดับไว้
- เปรียบเทียบเครื่องมือ agent แบบเทียบกันตรง ๆ — เทียบกันตรง ๆ ในด้านสถาปัตยกรรมและราคา
- อันดับ Mindber — ลีดเดอร์บอร์ดสดตามการ adoption ที่ติดตาม
- Manus vs Claude Cowork (2026) — สถาปัตยกรรม agent ต่างกันอย่างไรในทางปฏิบัติ
- โรคระบาด AI ที่ขึ้นหิ้ง (2026) — ทำไม agent ที่ deploy ส่วนใหญ่จึงไม่ถูกใช้
- ต้นทุนที่แท้จริงของเครื่องมือ AI (2026) — คณิตศาสตร์ token เบื้องหลังเศรษฐศาสตร์ของ loop
prompt engineering ตายไปแล้วเพราะ loop engineering หรือไม่?
ไม่ จุดยกระดับย้ายที่ ไม่ใช่ทักษะตายไป พรอมต์ยังต้องเขียนอยู่ — ความต่างคือตอนนี้ loop เป็นสิ่งที่เรียกมันตามตารางเวลา ไม่ใช่นักพัฒนาที่ทำด้วยมือ คุณภาพของพรอมต์ยังกำหนดคุณภาพของผลลัพธ์ภายในทุก loop สิ่งที่เปลี่ยนคือใคร (หรืออะไร) ตัดสินว่าจะเรียกพรอมต์เมื่อใด
harness engineering กับ loop engineering ต่างกันอย่างไร?
harness ติดตั้งอุปกรณ์ให้การรัน agent ครั้งเดียวด้วยเครื่องมือ สิทธิ์ และสัญญาณป้อนกลับ (รันโค้ด อ่าน error ตรวจสอบ output) loop คือชั้นเหนือมัน: มันทำให้ agent รันข้ามการรันหลายครั้ง สร้าง sub-agent ตรวจสอบผลลัพธ์ คงสถานะ และตัดสินใจว่าจะทำอะไรต่อ Harness = การรันครั้งเดียวที่ติดตั้งอุปกรณ์ Loop = ระบบที่คอยจัดตารางเวลา รัน และทบทวีความรู้ข้ามการรันหลายครั้ง
ฉันต้องการ loop engineering สำหรับโปรเจกต์เล็กหรือโปรเจกต์เดี่ยวหรือไม่?
ปกติไม่ หากงานเป็นครั้งเดียวหรือต้องพึ่งวิจารณญาณหนัก พรอมต์ที่ดีหนึ่งอันชนะ loop ทุกครั้ง loop คุ้มค่าโดยเฉพาะกับงานที่ทำซ้ำซึ่งมีนิยามความสำเร็จแบบไบนารี งานในโปรเจกต์เล็กส่วนใหญ่ไม่ถึงเกณฑ์นั้น — และภาระของการสร้าง loop กับงานที่รันสองครั้งคือการขาดทุนสุทธิ
เครื่องมือใดรองรับ loop engineering แบบ native ในวันนี้?
coding agent ที่สร้างขึ้นรอบการดำเนินการแบบวนซ้ำ — Claude Code, Codex ของ OpenAI, Cursor และ OpenClaw เป็นต้น ตรรกะ loop ส่วนใหญ่ตั้งอยู่รอบ agent มากกว่าอยู่ภายในมัน ดังนั้นส่วนใหญ่คุณต้องสร้างเองไม่ว่าจะใช้เครื่องมือใด มองหาเครื่องมือที่ให้: การรันตามตารางเวลา การมอบหมายให้ sub-agent การคงสถานะในตัว และเงื่อนไขหยุดที่ปรับตั้งได้ หมวด AI coding agents ของ Mindber ติดตามความครอบคลุมของโครงสร้างพื้นฐานปัจจุบันต่อเครื่องมือ
ความเสี่ยงที่ใหญ่ที่สุดของ loop engineering คืออะไร?
ต้นทุนบานปลายและ loop ที่ควบคุมไม่ได้ หากไม่มีเกณฑ์การยอมรับ การจำกัดงบประมาณ และกฎหยุดที่เด็ดขาด loop สามารถเผา token ได้ไม่จำกัดในขณะที่ดูเหมือนกำลังผลิตงาน ความเสี่ยงที่สอง: การออกแบบเกินจำเป็น การสร้าง loop สำหรับงานที่รันครั้งสองครั้งคือความสูญเปล่า ไม่ใช่ระบบอัตโนมัติ วินัยคือการรู้ว่างานของคุณตกอยู่ในถังไหนก่อนเริ่มสร้าง
ใครเป็นผู้บัญญัติคำว่า 'loop engineering'?
คำนี้ตกผลึกในเดือนมิถุนายน 2026 รอบ ๆ ข้อความสาธารณะของ Peter Steinberger (ผู้สร้าง OpenClaw ปัจจุบันอยู่ที่ OpenAI) และ Boris Cherny (หัวหน้า Claude Code ที่ Anthropic) โดยมี Addy Osmani จาก Google เขียนบทความอ้างอิงที่นิยามแนวคิดนี้และความสัมพันธ์เชิงชั้นของมันกับ prompt engineering, context engineering และ harness engineering
loop engineering ต่างจากระบบอัตโนมัติแบบดั้งเดิมอย่างไร?
ระบบอัตโนมัติแบบดั้งเดิมทำตามสคริปต์ที่ตายตัวกับระบบที่กำหนดแน่นอน loop engineering ใช้ AI agent — ดังนั้นเส้นทางการดำเนินการจึงปรับตัวได้ การกระทำถูกชี้นำด้วยภาษาธรรมชาติ และระบบรับมือกับสถานการณ์ที่ผู้เขียนโปรแกรมเดิมไม่ได้คาดการณ์ไว้ได้ โครงสร้าง loop (goal → act → observe → reflect → repeat) ยืมมาจากทฤษฎีการควบคุมแบบคลาสสิก แต่ agent ภายในมันไม่กำหนดแน่นอนและสามารถสรุปกว้าง (generalise) ได้ ข้อแลกเปลี่ยน: มีความสามารถมากกว่า คาดเดายากกว่า รันแพงกว่า
ฉันควร loop อะไรก่อน? จุดเริ่มต้นเชิงปฏิบัติสำหรับปี 2026
คำแนะนำของ Steinberger: เริ่มจากการอัป dependency, codemods หรือการแก้เทสต์ที่ไม่เสถียร งานเหล่านี้แคบ มีสัญญาณผ่าน/ไม่ผ่านแบบไบนารี (CI เขียว / diff สะอาด) รันได้โดยไม่ต้องใช้วิจารณญาณมนุษย์ และทำซ้ำตามตารางเวลา เมื่อมี loop ที่ใช้งานได้สำหรับหนึ่งในงานเหล่านี้แล้ว รูปแบบนั้นโอนถ่ายไปยังงานที่ซับซ้อนกว่าได้ — แต่หลังจากเวอร์ชันง่าย ๆ รันได้อย่างน่าเชื่อถือในงานโปรดักชันสักสองสามสัปดาห์เท่านั้น รูปแบบโอนถ่ายได้; ความไว้ใจต้องค่อย ๆ สร้างทีละน้อย
แหล่งที่มาและระเบียบวิธีบรรณาธิการ
บทความนี้สังเคราะห์จากข้อความสาธารณะปฐมภูมิ บทความที่เผยแพร่ และงานวิจัยของนักวิเคราะห์ที่อ้างอิงไว้ในเนื้อหา ทีมบรรณาธิการของ Mindber แยกป้ายข้อเท็จจริงที่ได้รับการยืนยันออกจากข้ออ้างเชิงคาดการณ์หรือช่วงเริ่มต้น ไม่มีการประเมินการนำ loop ไปใช้แบบเฉพาะเจาะจงโดยตรง — นี่คือการวิเคราะห์เชิงบรรณาธิการของข้อมูลสาธารณะจากแหล่งปฐมภูมิที่อ้างอิง
- [1]การกำหนดกรอบสาธารณะของ Peter Steinberger เรื่อง loop engineering และการออกแบบระบบที่ป้อนพรอมต์ให้ agentPublic post, June 2026 — 2026-06-07
- [2]Boris Cherny ว่าด้วยการเขียน loop แทนการป้อนพรอมต์ให้โมเดลโดยตรงAnthropic / Claude Code — public statements — 2026-06-07
- [3]บทความอ้างอิงของ Addy Osmani ที่นิยามชั้นต่าง ๆ ของ loop engineering และแสดงความขี้สงสัยต่อข้ออ้างในช่วงเริ่มต้นAddy Osmani — public writing — 2026-06-17
- [4]การจัดวางของ Gartner ที่ให้ agentic AI อยู่ที่จุดสูงสุดของความคาดหวังที่พองเกินจริง; ~17% ขององค์กรได้ deploy agent แล้วGartner Hype Cycle for Artificial Intelligence, 2026 — 2026-06-17
เจาะลึกสถาปัตยกรรม agent
Manus vs Claude Cowork (2026): Agent บนคลาวด์ vs บนเดสก์ท็อป
สถาปัตยกรรม ราคา และการปฏิบัติตามข้อกำหนด — การเปรียบเทียบฉบับชี้ขาดสำหรับนักสร้างที่เลือกระหว่าง AI agent แบบโฮสต์กับแบบ local-first
ต้นทุนที่แท้จริงของเครื่องมือ AI ในปี 2026
ราคา token ต้นทุนแฝง และเส้นแบ่ง token-rich vs token-poor ที่กำหนดว่ารูปแบบ loop ใดคุ้มทางการเงินสำหรับทีมของคุณ
Share this article
ประกาศทางกฎหมาย
สิ่งพิมพ์นี้เป็นบทวิจารณ์เชิงบรรณาธิการจากข้อมูลสาธารณะ และไม่ใช่คำแนะนำทางการเงิน กฎหมาย การลงทุน หรือวิชาชีพ ชื่อผลิตภัณฑ์ เครื่องหมายการค้า และเครื่องหมายการค้าจดทะเบียนที่กล่าวถึงเป็นทรัพย์สินของเจ้าของแต่ละราย การปรากฏของชื่อเหล่านั้นไม่ได้หมายถึงการรับรองหรือความเกี่ยวข้อง การวิเคราะห์ของ Mindber สะท้อนดุลยพินิจเชิงบรรณาธิการจากสัญญาณสาธารณะและอาจเปลี่ยนแปลงได้โดยไม่ต้องแจ้งให้ทราบ คะแนนไม่ใช่คำแนะนำให้ซื้อ ขาย หรือถือครอง ไม่มีความสัมพันธ์ทางการค้าระหว่าง Mindber กับผู้ให้บริการที่ประเมิน เว้นแต่จะเปิดเผยเป็นลายลักษณ์อักษร สิ่งพิมพ์นี้อยู่ภายใต้กฎหมายของมาเลเซีย ข้อพิพาทใด ๆ ที่เกิดจากหรือเกี่ยวข้องกับสิ่งพิมพ์นี้ให้อยู่ภายใต้เขตอำนาจศาลเฉพาะของศาลมาเลเซีย
สร้างโดย AI · รายงานนี้สร้างขึ้นโดยใช้โมเดลภาษา AI ที่ฝึกจากข้อมูลที่เปิดเผยต่อสาธารณะ รายงานสะท้อนการวิเคราะห์เชิงบรรณาธิการ ณ เวลาที่สร้าง และไม่ได้เป็นผลจากการทดสอบผลิตภัณฑ์โดยตรง การตรวจสอบอิสระโดยนักวิเคราะห์มนุษย์ หรือการรับรองเชิงพาณิชย์ คะแนน การประเมิน และข้อกล่าวอ้างทั้งหมดมาจากสัญญาณที่ Mindber จัดทำดัชนี ณ เวลาที่สร้าง และอาจเปลี่ยนแปลงได้โดยไม่ต้องแจ้งให้ทราบ Mindber และผู้ดำเนินการไม่รับประกันความถูกต้อง ความครบถ้วน หรือความเหมาะสมสำหรับวัตถุประสงค์ในการตัดสินใจเชิงพาณิชย์ใด ๆ รายงานนี้มีไว้เพื่อให้ข้อมูลเท่านั้น