Loop Engineering: Why Top Engineers Stopped Prompting Their AI
guideUpdated 8 min read
Design the system that prompts your AI agents, not the prompts themselves. What works in production today, what doesn't, and when to skip it entirely.

Last verified: 2026-06-17. Statements attributed to Peter Steinberger, Boris Cherny, and Addy Osmani are sourced from their publicly available posts and essays as of this date. The field is moving fast — check linked sources for the most current positions.
By Frankie C. · Senior Market Researcher, Mindber. Tracks 500+ AI/SaaS tools across SEA markets via the Mindber Innovation Index methodology.
On 7 June 2026, a developer named Peter Steinberger posted two sentences that pulled millions of views and reopened an argument the AI-coding world thought it had settled. His point: stop typing prompts into your coding agent. Build the system that prompts it for you. Days earlier, Boris Cherny — who runs Claude Code at Anthropic — had made the same observation from the inside: he doesn't prompt the model anymore. He writes loops, and the loops do the prompting.
For background on how Mindber rates the tools this matters for, see the AI coding agents category and the methodology behind the Mindber Innovation Index.
The post that reopened the debate: Peter Steinberger on building the loop instead of typing the prompts. Source: Peter Steinberger on X, June 2026.
That idea now has a name: loop engineering. Most of the coverage since has been breathless. This is the de-hyped version — what it is, what works in production today, what doesn't yet, and when not to build a loop at all.
What is loop engineering?
Loop engineering is the practice of designing a system that runs an AI agent in cycles — set a goal, take an action, observe the result, reflect, and repeat — until the goal is met or the system hands control back to a human.
The shift is about who does the prompting. Instead of a developer steering the agent turn by turn, they build the loop that steers it. Steinberger (creator of the open-source agent project OpenClaw, now at OpenAI) framed the job as designing "loops that prompt your agents." Addy Osmani, the Google engineer whose essay on loop engineering became the reference text, describes a loop as a recursive goal: define the purpose, iterate until done.
The one-line test: If you find yourself re-running the same prompt — with slightly different context each time — you already have a manual loop. Loop engineering is what you build so you stop doing that by hand.
Where loop engineering fits: four layers of the stack
Loop engineering didn't appear from nowhere. It's the top of a stack that grew as agents got more capable. Each layer answers a fundamentally different question.
The four layers of AI engineering — each builds on the last
- 1
Prompt Engineering
The early stageThe question it answers: how do I phrase one request? What you control: the wording of a single input. The core lever is precise human expression — asking the model clearly enough to lift its grasp of one prompt. - 2
Context / Workflow Engineering
The intermediate stageThe question: how do I chain steps and feed background? What you control: the information and sequence the agent sees. Deterministic logic chains plus fuller project context raise the model's grasp of a large, multi-step task. - 3
Harness Engineering
The runtime layerThe question: how do I equip one agent run? What you control: tools, permissions, and verifiable signals — run the code, read the error. You build the execution environment and hand the agent the right tools, access, and checkable run signals. - 4
Loop Engineering
The current frontierThe question: how do I keep the agent running and improving on its own? What you control: the system that triggers, assigns, verifies, persists state, and decides what's next — a closed loop that lets the agent self-correct instead of waiting for a human to check.
The clean way to hold the distinction: the harness equips a single run; the loop is what keeps poking the agent on a schedule, spawns helpers, feeds itself across many runs, and compounds what it learns.
Most debate about "prompting vs. engineering" collapses this whole stack into one thing. They're not the same thing, and conflating them produces the wrong tool for the job at every layer.
Anatomy of a real loop
Most people's mental model of an agent: Goal → Plan → Execute → Output. That's where they stop — and it's exactly why their "loop" isn't one. It runs once and quits.
A real loop adds two mandatory steps after the output:
The six-step loop — what separates a loop from a one-shot
- 1
Set a goal
Define the target with a measurable acceptance criterion. 'Improve the dashboard' fails this test. 'Cut initial load time by 30% without breaking the filter component' passes it. Without a concrete stop condition, the loop runs forever or quits arbitrarily — both failures. - 2
Make a plan
The agent decomposes the goal into discrete, executable steps with verifiable outputs at each stage. The plan is not fixed — it updates when Observe/Reflect feed new information back in. - 3
Execute
The agent takes actions: writes code, calls APIs, edits files, runs tests, reads error messages. The harness determines what it can access. This is where most developer time is spent — but it's only one of six steps. - 4
Output
The agent produces a result: a diff, a report, a test outcome. This is where most DIY 'loops' stop. It's also where a real loop is just getting started — the output is the input to the next two steps. - 5
Observe
Look at the result AND the steps that produced it — not just the final answer. A common production pattern: a second, independent model (the checker) reviews the work against the original spec. The checker's only job is to find what the maker missed. - 6
Reflect
Decide what to change. Adjust the goal, update the plan, and go again. The checker pushes the maker to iterate instead of declaring victory early. This is where the loop earns its name — without Reflect, you have a pipeline, not a loop.
What's inside a production loop
A loop that survives contact with real work has six components. Missing any one of them is usually where failure happens.
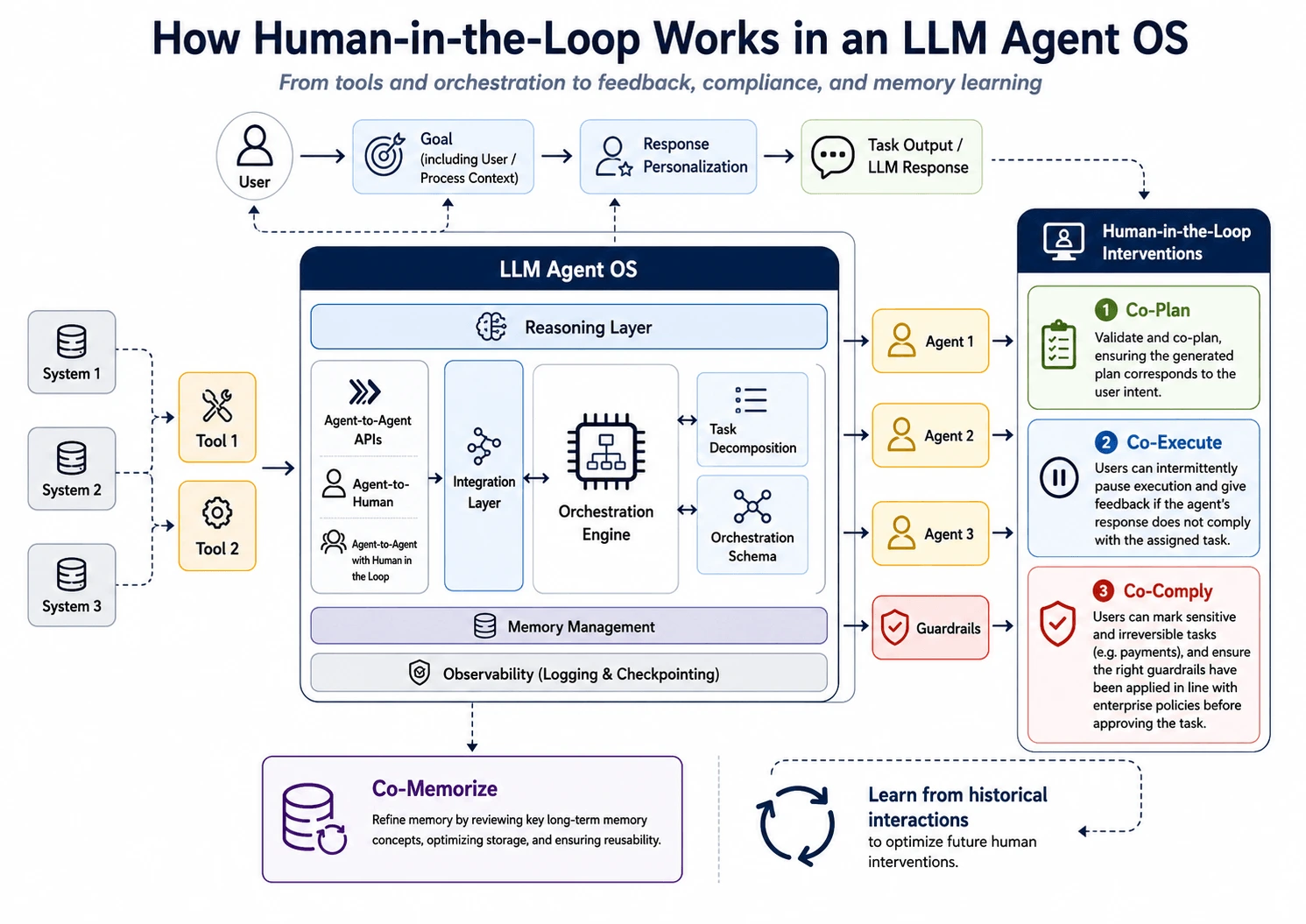
The same six parts mapped onto a full agent OS: tools and orchestration feed the agents; human gates (Co-Plan / Co-Execute / Co-Comply) and memory close the loop. Mindber original diagram.
| Dimension | Component | What it does | Without it |
|---|---|---|---|
| Automation | The heartbeat. Something wakes the loop: a schedule, a webhook, a file-change event. Without it, you have a one-off chat. | A chat session, not a loop. Requires a human to start every run. | |
| Workspace isolation | Parallel agents need separate working copies (git worktrees, scoped permissions) so they don't overwrite each other's changes. | Agents collide mid-run, producing corrupted or rolled-back work. | |
| Skills | Codified experience: reusable prompt templates, standard verification procedures, domain knowledge files. Anything done more than once should become a skill — the next time is free. | Every cycle reinvents the wheel. No compounding. The loop is expensive and dumb. | |
| Connectors | APIs and tools that let the agent act in the world: git, email, calendar, payments, MCP tool servers. | The agent can reason but can't act. A loop that can only write is a loop that can't ship. | |
| Sub-agents (maker + checker) | One agent executes at speed (maker). A second independent agent reviews against the spec (checker). Neither has the final word alone. | No internal quality gate. The loop ships whatever the first pass produces. | |
| Memory | The loop writes progress, errors, and lessons to a persistent store. Each run builds on the last. | Every cycle starts from zero. No compounding. The system never gets smarter. |
Steinberger's most durable rule: Anything you do more than once should become a skill, so the next time is free. A loop with no reusable skills inside it is just an infinite loop wrapped around a stranger. Skills are the compounding mechanism — without them, you're renting intelligence run by run instead of owning it.
The four guardrails that make it safe to leave running
Components make a loop run. These four make it safe to walk away — the difference between an autonomous system and an expensive mistake you discover on the next credit card bill.
| Dimension | Guardrail | What it prevents | How to implement |
|---|---|---|---|
| Acceptance criteria | Infinite loops or arbitrary quitting mid-task | Define 'done' in binary terms before the loop starts. Measurable, verifiable, automated. If you can't describe done in code, don't start the loop. | |
| Permission boundaries | Agents overstepping scope — deleting files they shouldn't touch, merging without review, triggering payments | Least privilege. Decide what the agent may change, delete, merge, or pay for before it runs. The scope decision is yours; the enforcement is the boundary. | |
| Human gate | Irreversible mistakes executed at machine speed | For sensitive or irreversible calls (money out, production merges, schema changes), the loop pauses and routes to a human. Not optional for high-stakes operations. | |
| Observability | Silent failure, untraceable errors, runaway cost | Every step must be auditable. You tune a loop by watching where it breaks — not by guessing. Logs, step traces, and budget meters are not optional. |
The honest part: what the hype cycle skips
The people closest to this work are the most cautious about it. That's worth paying attention to.
Addy Osmani, who wrote the canonical essay, openly calls himself skeptical and stresses it's early — and that token costs swing wildly depending on whether you're "token rich or token poor." An unbounded loop can quietly burn a fortune while looking like it's making progress.
The ground truth on agent deployment
~17%
of organisations have actually deployed agents
Gartner Hype Cycle 2026
Peak
Agentic AI on Gartner's inflated-expectations curve
Gartner Hype Cycle for AI, 2026
48h
Max value window for rapid-response agent demos
Mindber editorial analysis
Steinberger draws a clear line between what works now and what doesn't:
Works today — proven in production:
- Several agents running parallel issues, with a human reviewing at merge
- Narrow, verifiable pipelines: dependency bumps, codemods, flaky-test fixes
- Tasks where "done" has a binary, automated signal (tests pass / diff is clean / endpoint returns 200)
Doesn't work yet — the honest admission:
- "Idea in, product out" with no human holding the vision
- Pre-committing to a fixed end state and fully automating the path to it — that's waterfall with extra steps
- Good software still gets discovered through iteration, not declared up front
The Gartner caveat: Peak of inflated expectations doesn't mean the technology is fake. It means the demos are well ahead of the deployments, per the Gartner Hype Cycle for Artificial Intelligence. Source: Gartner Hype Cycle for Artificial Intelligence, 2026, Jun 17, 2026 Roughly 83% of organisations haven't deployed agents at all. The gap between what's shown at conferences and what runs in production is real, wide, and closing slower than the hype suggests.
See also: The true cost of AI tools in 2026 — the token cost math behind "token rich vs. token poor."
When to build a loop — and when not to
One question determines the answer: does the work repeat, and is "done" objectively measurable?
Should you build a loop?
Build the loop
- Dependency bumps and codemods
- Flaky test detection and fix cycles
- Scheduled content or data pipelines
- Code review automation on PRs
- Regression testing across deploys
Just write the prompt
- Single-use analysis or investigation
- One-time migration or data move
- First-pass exploration of a codebase
- Ad hoc research with no repeat pattern
Do not hand it to a loop
- 'Come up with a better product strategy'
- Open-ended creative direction
- Decisions requiring business context a loop can't hold
- Work with no measurable success signal
The bootstrap reality for cost-conscious builders
For solo builders and small teams — especially across Southeast Asia, where most builders are not "token rich" — cost discipline matters more than ambition. The Mindber Innovation Index tracks tool cost-efficiency specifically: how gracefully each tool handles resource constraints without sacrificing output quality.
Three rules keep a loop from becoming a money pit:
-
Cap a per-run token budget before walking away. Not a vague limit — a hard number, enforced at the code layer. Token budgets are the credit card limit on your loop. If the limit isn't in the code, it doesn't exist.
-
Start with one narrow, verifiable task before chaining several together. Complexity compounds fast. Earn trust in the simple version before adding stages. The Mindber Functionality Score for Claude Code and comparable tools specifically measures this: how well does the tool handle budget guardrails and graceful failure modes in practice?
-
Stop automatically when the same error, an empty diff, or a failing test repeats N times in a row. A loop that can't stop itself isn't autonomous — it's just expensive. The stop rule is not optional.
The Steinberger principle: A loop that pre-commits to a fixed end state and fully automates the path to it has quietly reinvented waterfall. Software still gets discovered through iteration — not declared up front. Build in checkpoints. Keep humans in the decision loop for anything irreversible.
What this means for tool selection
Not all agent runtimes support loop patterns equally. The Mindber Innovation Index tracks which tools in the AI coding agents category have shipped native loop infrastructure — scheduled execution, sub-agent delegation, state persistence, budget caps — versus which require you to build all of it yourself from scratch.
Tools like Claude Code, OpenAI's Codex, Cursor, and OpenClaw ship with varying degrees of this infrastructure baked in. The loop logic sits around the agent — so much of it you build regardless of which tool you choose. The Mindber Functionality Score captures how much scaffolding each tool provides out of the box versus how much you own. That delta matters most for small teams that can't afford to rebuild the same plumbing twice.
Where to dig deeper:
- Claude Code product page — the Mindber Functionality Score and capability breakdown
- AI coding agents category — every tracked tool in the space, ranked
- Compare agent tools side by side — head-to-head on architecture and pricing
- Mindber rankings — the live leaderboard by tracked adoption
- Manus vs Claude Cowork (2026) — how agent architectures differ in practice
- The AI shelfware epidemic (2026) — why most deployed agents go unused
- The true cost of AI tools (2026) — the token math behind loop economics
Is prompt engineering dead because of loop engineering?
No. The leverage point moved, not the skill. Prompts still need to be written — the difference is that a loop is now the thing calling them on a schedule, not a developer doing it by hand. Prompt quality still determines output quality inside every loop. What changed is who (or what) decides when to call the prompt.
What's the difference between harness engineering and loop engineering?
A harness equips a single agent run with tools, permissions, and feedback signals (run the code, read the error, verify the output). A loop is the layer above it: it keeps the agent running across many runs, spawns sub-agents, verifies results, persists state, and decides what to do next. Harness = one run equipped. Loop = the system that keeps scheduling, running, and compounding knowledge across many runs.
Do I need loop engineering for a small or solo project?
Usually not. If the work is one-off or heavily judgement-dependent, one good prompt beats a loop every time. Loops pay off specifically on repetitive work with a binary definition of success. Most small-project tasks don't meet that bar — and the overhead of building a loop on something that runs twice is a net loss.
Which tools support loop engineering natively today?
Coding agents built around iterative execution — Claude Code, OpenAI's Codex, Cursor, and OpenClaw among them. The loop logic largely sits around the agent rather than inside it, so much of it you build yourself regardless of tool. Look for tools that provide: scheduled execution, sub-agent delegation, built-in state persistence, and configurable stop conditions. Mindber's AI coding agents category tracks current infrastructure coverage per tool.
What's the biggest risk of loop engineering?
Cost overruns and runaway loops. Without acceptance criteria, a budget cap, and a hard stop rule, a loop can burn tokens indefinitely while appearing productive. The second risk: over-engineering. Building a loop for a task that runs once or twice is waste, not automation. The discipline is knowing which bucket your work falls into before you start building.
Who coined the term 'loop engineering'?
The term crystallised in June 2026 around public statements by Peter Steinberger (creator of OpenClaw, now at OpenAI) and Boris Cherny (head of Claude Code at Anthropic), with Addy Osmani of Google writing the reference essay that defined the concept and its layered relationship to prompt engineering, context engineering, and harness engineering.
How is loop engineering different from traditional automation?
Traditional automation follows fixed scripts against deterministic systems. Loop engineering uses AI agents — so the execution path is adaptive, the actions are natural-language directed, and the system can handle situations the original programmer didn't anticipate. The loop structure (goal → act → observe → reflect → repeat) is borrowed from classical control theory, but the agent inside it is non-deterministic and can generalise. The tradeoff: more capable, harder to predict, more expensive to run.
What should I loop first? A practical starting point for 2026.
Steinberger's recommendation: start with dependency bumps, codemods, or flaky-test fixes. These tasks are narrow, have a binary pass/fail signal (CI is green / diff is clean), run without human judgement, and repeat on a schedule. Once a working loop exists for one of these, the pattern transfers to more complex tasks — but only after the simple version has run reliably in production for a few weeks. The pattern transfers; the trust has to be earned incrementally.
Sources and editorial methodology
This article synthesises primary public statements, published essays, and analyst research cited inline. Mindber's editorial team labels established facts separately from speculative or early-stage claims. No direct evaluation of specific loop implementations was conducted — this is editorial analysis of public information from cited primary sources.
- [1]Peter Steinberger's public framing of loop engineering and designing systems that prompt agentsPublic post, June 2026 — 2026-06-07
- [2]Boris Cherny on writing loops instead of prompting models directlyAnthropic / Claude Code — public statements — 2026-06-07
- [3]Addy Osmani's reference essay defining the layers of loop engineering and expressing scepticism about early-stage claimsAddy Osmani — public writing — 2026-06-17
- [4]Gartner placement of agentic AI at peak of inflated expectations; ~17% of organisations have deployed agentsGartner Hype Cycle for Artificial Intelligence, 2026 — 2026-06-17
Go deeper on agent architecture
Manus vs Claude Cowork (2026): Cloud vs Desktop Agent
Architecture, pricing, and compliance — the definitive comparison for builders choosing between hosted and local-first AI agents.
The True Cost of AI Tools in 2026
Token pricing, hidden costs, and the token-rich vs token-poor divide that determines which loop patterns are financially viable for your team.
Share this article
Legal notice
This publication constitutes editorial commentary on publicly available information and does not constitute financial, legal, investment, or professional advice. Product names, trademarks, and registered trademarks referenced herein are the property of their respective owners; their appearance does not imply endorsement or affiliation. Mindber's analysis reflects editorial judgment based on public signals and is subject to change without notice. Scores are not buy, sell, or hold recommendations. No commercial relationship exists between Mindber and the vendors evaluated unless separately disclosed in writing. This publication is governed by the laws of Malaysia. Any dispute arising from or in connection with this publication shall be submitted to the exclusive jurisdiction of the courts of Malaysia.
AI-generated · This report was generated using AI language models trained on publicly available data. It reflects editorial analysis at the time of generation and is not the result of hands-on product testing, independent verification by a human analyst, or a commercial endorsement. All scores, assessments, and claims are derived from signals indexed by Mindber at generation time and are subject to change without notice. Mindber and its operators make no warranty of accuracy, completeness, or fitness for any commercial decision-making purpose. This report is for informational purposes only.